ブランチとは
Git のブランチの仕組みについてきちんと理解するには、少し後戻りして Git がデータを格納する方法を知っておく必要があります。第 1 章で説明したように、Git はチェンジセットや差分としてデータを保持しているのではありません。そうではなく、スナップショットとして保持しています。
Git にコミットすると、Git はコミットオブジェクトを作成して格納します。このオブジェクトには、あなたがステージしたスナップショットへのポインタや作者・メッセージのメタデータ、そしてそのコミットの直接の親となるコミットへのポインタが含まれています。最初のコミットの場合は親はいません。通常のコミットの場合は親がひとつ存在します。複数のブランチからマージした場合は、親も複数となります。
これを視覚化して考えるために、ここに 3 つのファイルを含むディレクトリがあると仮定しましょう。3 つのファイルをすべてステージしてコミットしたところです。ステージしたファイルについてチェックサム (第 1 章で説明した SHA-1 ハッシュ) を計算し、そのバージョンのファイルを Git ディレクトリに格納し (Git はファイルを blob として扱います)、そしてそのチェックサムをステージングエリアに追加します。
$ git add README test.rb LICENSE
$ git commit -m 'initial commit of my project'
git commit を実行すると、プロジェクト内全ディレクトリのチェックサムが計算され、tree オブジェクトとして Git リポジトリに格納されます。続いて、メタデータおよびさきほどの tree オブジェクトへのポインタを含むコミットオブジェクトを作成します。これで、必要に応じてこのスナップショットを再作成できるようになります。
この時点で、Git リポジトリには 5 つのオブジェクトが含まれています。3 つのファイルそれぞれの中身をあらわす blob オブジェクト、ディレクトリの中身の一覧とどのファイルがどの blob に対応するかをあらわすツリーオブジェクト、そしてそのルートツリーおよびすべてのメタデータへのポインタを含むコミットオブジェクトです。Git リポジトリ内のデータを概念図であらわすと、図 3-1 のようになります。
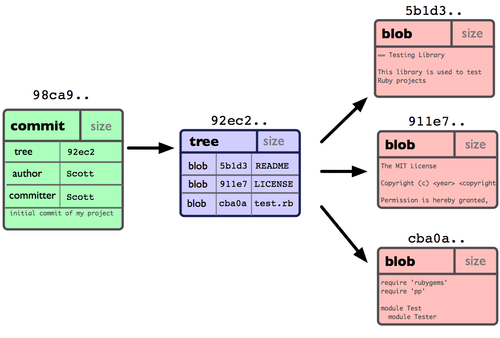
図 3-1. ひとつのコミットをあらわすリポジトリ上のデータ
なんらかの変更を終えて再びコミットすると、次のコミットには直近のコミットへのポインタが格納されます。さらに 2 回のコミットを終えた後の履歴は、図 3-2 のようになるでしょう。
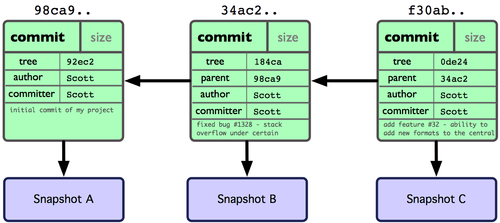
図 3-2. 複数のコミットに対応する Git オブジェクト
Git におけるブランチとは、単にこれら三つのコミットを指す軽量なポインタに過ぎません。Git のデフォルトのブランチ名は master です。最初にコミットした時点で、直近のコミットを指す master ブランチが作られます。その後コミットを繰り返すたびに、このポインタは自動的に進んでいきます。
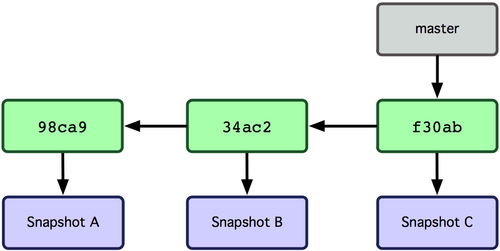
図 3-3. コミットデータの歴史を指すブランチ
新しいブランチを作成したら、いったいどうなるのでしょうか? 単に新たな移動先を指す新しいポインタが作られるだけです。では、新しい testing ブランチを作ってみましょう。次の git branch コマンドを実行します。
$ git branch testing
これで、新しいポインタが作られます。現時点ではふたつのポインタは同じ位置を指しています (図 3-4 を参照ください)。
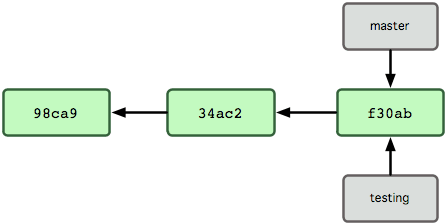
図 3-4. 複数のブランチがコミットデータの履歴を指す例
Git は、あなたが今どのブランチで作業しているのかをどうやって知るのでしょうか? それを保持する特別なポインタが HEAD と呼ばれるものです。これは、Subversion や CVS といった他の VCS における HEAD の概念とはかなり違うものであることに注意しましょう。Git では、HEAD はあなたが作業しているローカルブランチへのポインタとなります。今回の場合は、あなたはまだ master ブランチにいます。git branch コマンドは新たにブランチを作成するだけであり、そのブランチに切り替えるわけではありません (図 3-5 を参照ください)。
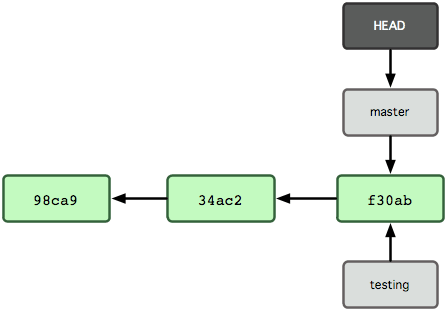
図 3-5. 現在作業中のブランチを指す HEAD
ブランチを切り替えるには git checkout コマンドを実行します。それでは、新しい testing ブランチに移動してみましょう。
$ git checkout testing
これで、HEAD は testing ブランチを指すようになります (図 3-6 を参照ください)。
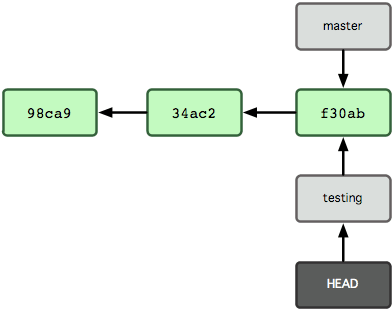
図 3-6. ブランチを切り替えると、HEAD の指す先が移動する
それがどうしたって? では、ここで別のコミットをしてみましょう。
$ vim test.rb
$ git commit -a -m 'made a change'
図 3-7 にその結果を示します。
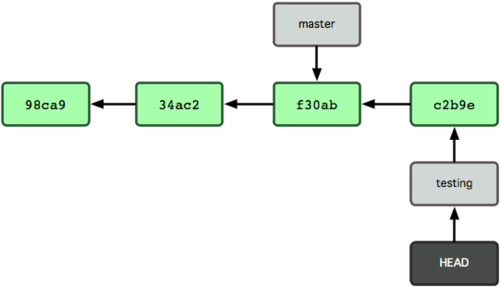
図 3-7. HEAD が指すブランチが、コミットによって移動する
興味深いことに、testing ブランチはひとつ進みましたが master ブランチは変わっていません。git checkout でブランチを切り替えたときの状態のままです。それでは master ブランチに戻ってみましょう。
$ git checkout master
図 3-8 にその結果を示します。
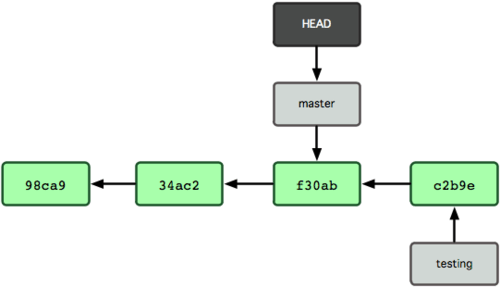
図 3-8. チェックアウトによって HEAD が別のブランチに移動する
このコマンドは二つの作業をしています。まず HEAD ポインタが指す先を master ブランチに戻し、そして作業ディレクトリ内のファイルを master が指すスナップショットの状態に戻します。つまり、この時点以降に行った変更は、これまでのプロジェクトから分岐した状態になるということです。これは、testing ブランチで一時的に行った作業を巻き戻したことになります。ここから改めて別の方向に進めるということになります。
それでは、ふたたび変更を加えてコミットしてみましょう。
$ vim test.rb
$ git commit -a -m 'made other changes'
これで、プロジェクトの歴史が二つに分かれました (図 3-9 を参照ください)。新たなブランチを作成してそちらに切り替え、何らかの作業を行い、メインブランチに戻って別の作業をした状態です。どちらの変更も、ブランチごとに分離しています。ブランチを切り替えつつそれぞれの作業を進め、必要に応じてマージすることができます。これらをすべて、シンプルに branch コマンドと checkout コマンドで行えるのです。
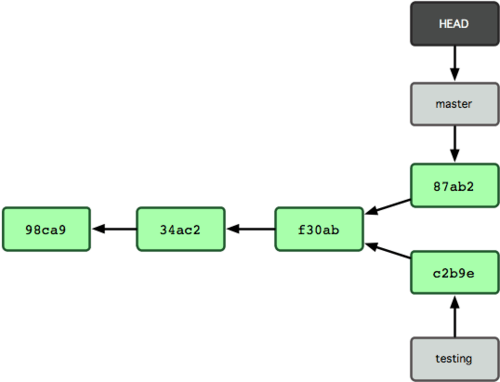
図 3-9. ブランチの歴史が分裂した
Git におけるブランチとは、実際のところ特定のコミットを指す 40 文字の SHA-1 チェックサムだけを記録したシンプルなファイルです。したがって、ブランチを作成したり破棄したりするのは非常にコストの低い作業となります。新たなブランチの作成は、単に 41 バイト (40 文字と改行文字) のデータをファイルに書き込むのと同じくらい高速に行えます。
これが他の大半の VCS ツールのブランチと対照的なところです。他のツールでは、プロジェクトのすべてのファイルを新たなディレクトリにコピーしたりすることになります。プロジェクトの規模にもよりますが、これには数秒から数分の時間がかかることでしょう。Git ならこの処理はほぼ瞬時に行えます。また、コミットの時点で親オブジェクトを記録しているので、マージの際にもどこを基準にすればよいのかを自動的に判断してくれます。そのためマージを行うのも非常に簡単です。これらの機能のおかげで、開発者が気軽にブランチを作成して使えるようになっています。
では、なぜブランチを切るべきなのかについて見ていきましょう。