Git 개체
Git은 Content-addressable 파일시스템이다. 이게 무슨 말이냐 하면 Git이 단순한 Key-Value 데이터 저장소라는 것이다. 어떤 형식의 데이터라도 집어넣을 수 있고 해당 Key로 언제든지 데이터를 다시 가져올 수 있다. Plumbing 명령어 hash-object에 데이터를 주면 .git 디렉토리에 저장하고 그 key를 알려준다. 우선 Git 저장소를 새로 만들고 objects 디렉토리에 뭐가 들어 있는지 확인한다:
$ mkdir test
$ cd test
$ git init
Initialized empty Git repository in /tmp/test/.git/
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
$
아무것도 없다. Git은 objects 디렉토리를 만들고 그 밑에 pack과 info 디렉토리도 만든다. 아직 빈 디렉토리일 뿐 파일은 아무것도 없다. Git 데이터베이스에 텍스트 파일을 저장해보자:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
이 명령은 표준입력으로 들어오는 데이터를 저장할 수 있다. -w 옵션을 줘야 실제로 저장한다. -w가 없으면 저장하지 않고 key만 보여준다. 그리고 --stdin 옵션을 주면 표준입력으로 입력되는 데이터를 읽는다. 이 옵션이 없으면 파일 경로를 알려줘야 한다. hash-object 명령이 출력하는 것은 40자 길이의 체크섬 해시다. 이 해시는 헤더 정보와 데이터 모두에 대한 SHA-1 해시이다. 헤더 정보는 차차 자세히 살펴볼 것이다. Git이 저장한 데이터를 알아보자:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
objects 디렉토리에 파일이 하나 새로 생겼다. Git은 데이터를 저장할 때 데이터와 헤더로 생성한 SHA-1 체크섬으로 파일 이름을 짓는다. 해시의 처음 두 글자를 따서 디렉토리 이름에 사용하고 나머지 38글자를 파일 이름에 사용한다. 데이터는 새로 만든 파일에 저장한다.
cat-file 명령으로 저장한 데이터를 불러올 수 있다. 이 명령은 Git 개체를 살펴보고 싶을 때 맥가이버칼처럼 사용할 수 있다. cat-file 명령에 -p 옵션을 주면 파일 내용이 출력된다:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
다시 한 번 데이터를 Git 저장소에 추가하고 불러와 보자. Git이 파일 버전을 관리하는 방식을 이해할 수 있도록 가상의 상황을 만들어 살펴본다. 우선 새 파일을 하나 만들고 Git 저장소에 저장한다:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
그리고 그 파일을 수정하고 다시 저장한다:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
이제 데이터베이스에는 데이터가 두 가지 버전으로 저장돼 있다:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
파일의 내용을 첫 번째 버전으로 되돌리려 본다:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1
다시 두 번째 버전을 적용한다:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2
파일의 SHA-1 키를 외워서 사용하는 것은 너무 어렵다. 게다가 원래 파일의 이름은 저장하지도 않았다. 단지 파일 내용만 저장했을 뿐이다. 이런 종류의 개체를 Blob 개체라고 부른다. cat-file -t 명령으로 해당 개체가 무슨 개채인지 확인할 수 있다:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob
Tree 개체
다음은 Tree 개체를 살펴보자. 이 Tree 개체에 파일 이름을 저장한다. 파일 여러 개를 한꺼번에 저장할 수도 있다. Git은 유닉스 파일 시스템과 비슷한 방법으로 저장하지만 좀 더 단순하다. 모든 것을 Tree와 Blob 개체로 저장한다. Tree는 유닉스의 디렉토리에 대응되고 Blob은 Inode나 일반 파일에 대응된다. Tree 개체 하나는 항목을 여러 개 가질 수 있다. 그리고 그 항목에는 Blob 개체나 하위 Tree 개체를 가리키는 SHA-1 포인터, 파일 모드, 개체 타입, 파일 이름이 들어 있다. simplegit 프로젝트의 마지막 Tree 개체를 살펴보자:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
master^{tree} 구문은 master 브랜치가 가리키는 Tree 개체를 말한다. lib은 디렉토리인데 Blob 개체가 아니고 다른 Tree 개체다:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
Git이 저장하는 데이터는 대강 그림 9-1과 같다.
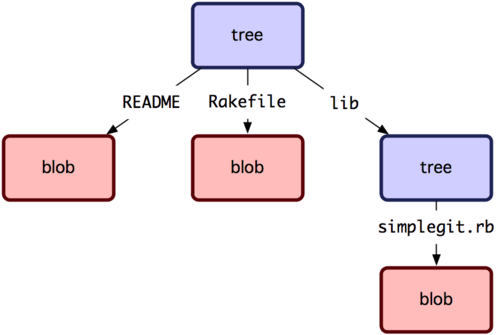
그림 9-1. 단순화한 Git 데이터 모델
직접 Tree 개체를 만들어 보자. Git은 일반적으로 Staging Area(Index)의 상태대로 Tree 개체를 만들고 기록한다. 그래서 Tree 개체를 만들려면 우선 Staging Area에 파일을 추가해서 Index를 만들어야 한다. 우선 Plumbing 명령어 update-index로 test.txt 파일만 들어 있는 Index를 만든다. 이 명령어는 파일을 인위적으로 Staging Area에 추가하는 명령다. 아직 Staging Area에 없는 파일이기 때문에 --add 옵션을 꼭 줘야 한다(사실 아직 Staging Area도 설정하지 않았다). 그리고 디렉토리에 있는 파일이 아니라 데이터베이스에 있는 파일을 추가하는 것이기 때문에 --cacheinfo 옵션이 필요하다. 파일 모드, SHA-1 해시, 파일 이름 정보도 입력한다:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt
여기서 파일 모드는 보통의 파일을 나타내는 100644로 지정했다. 실행파일이라면 100755로 지정하고 심볼릭 링크라면 120000으로 지정한다. 이런 파일 모드는 유닉스에서 가져오긴 했지만, 유닉스 모드를 전부 사용하지는 않는다. Blob 파일에는 이 세 가지 모드만 사용한다. 디렉토리나 서브모듈에는 다른 모드를 사용한다.
Staging Area를 Tree 개체로 저장할 때는 write-tree 명령을 사용한다. write-tree 명령은 Tree 개체가 없으면 자동으로 생성하므로 -w 옵션이 필요 없다:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
아래 명령으로 이 개체가 Tree 개체라는 것을 확인한다:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
파일을 새로 하나 추가하고 test.txt 파일도 두 번째 버전을 만든다. 그리고 나서 Tree 개체를 만든다:
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txt
새 파일인 new.txt와 새로운 버전의 test.txt 파일까지 Staging Area에 추가했다. 현재 상태의 Staging Area를 새로운 Tree 개체로 기록하면 어떻게 보이는지 살펴보자:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
이 Tree 개체에는 파일이 두 개 있고 test.txt 파일의 SHA 값도 두 번째 버전인 1f7a7a1이다. 재미난 걸 해보자. 처음에 만든 Tree 개체를 하위 디렉토리로 만들 수 있다. read-tree 명령으로 Tree 개체를 읽어 Staging Area에 추가한다. --prefix 옵션을 주면 Tree 개체를 하위 디렉토리로 추가할 수 있다.
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
이 Tree 개체로 워킹 디렉토리를 만들면 파일 두 개와 bak이라는 하위 디렉토리가 생긴다. 그리고 bak 디렉토리 안에는 test.txt 파일의 처음 버전이 들어 있다. 그림 9-2와 같은 구조로 데이터가 저장된다.
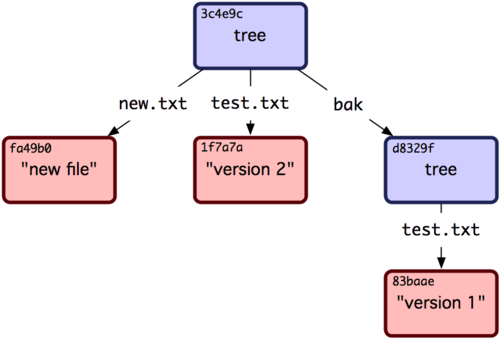
그림 9-2. 현재 Git 데이터 구조
커밋 개체
각기 다른 스냅샷을 나타내는 Tree 개체를 세 개 만들었다. 하지만, 여전히 이 스냅샷을 불러 오려면 SHA-1 값을 기억하고 있어야 한다. 스냅샷을 누가, 언제, 왜 저장했는지에 대한 정보는 아예 없다. 이런 정보는 커밋 개체에 저장된다:
커밋 개체는 commit-tree 명령으로 만든다. 이 명령에 커밋 개체에 대한 설명과 Tree 개체의 SHA-1 값 한 개를 넘긴다. 앞서 저장한 첫 번째 Tree를 가지고 아래와 같이 만들어 본다:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d
새로 생긴 커밋 개체를 cat-file 명령으로 확인해보자:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commit
커밋 개체의 형식은 간단하다. 해당 스냅샷에서 최상단 Tree를(역주 - 루트 디렉터리 같은) 하나 가리킨다. 그리고 user.name과 user.email 설정에서 가져온 Author/Committer 정보, 시간 정보, 그리고 한 줄 띄운 다음 커밋 메시지가 들어 간다.
이제 커밋 개체를 두 개 더 만들어 보자. 각 커밋 개체는 이전 개체를 가리키도록 한다:
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9
세 커밋 개체는 각각 해당 스냅샷을 나타내는 Tree 개체를 하나씩 가리키고 있다. 이상해 보이겠지만 우리는 진짜 Git 히스토리를 만들었다. 마지막 커밋 개체의 SHA-1 값을 주고 git log 명령을 실행하면 아래와 같이 출력한다:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletions(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
놀랍지 않은가! 방금 우리는 고수준 명령어 없이 저수준의 명령으로만 Git 히스토리를 만들었다. 지금 한 일이 git add와 git commit 명령을 실행했을 때 Git 내부에서 일어나는 일이다. Git은 변경된 파일을 Blob 개체로 저장하고 현 Index에 따라서 Tree 개체를 만든다. 그리고 이전 커밋 개체와 최상위 Tree 개체를 참고해서 커밋 개체를 만든다. 즉 Blob, Tree, 커밋 개체가 Git의 주요 개체이고 이 개체는 전부 .git/objects 디렉토리에 저장된다. 이 예제에서 생성한 개체는 아래와 같다:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
내부의 포인터를 따라가면 그림 9-3과 같은 그래프가 그려진다.
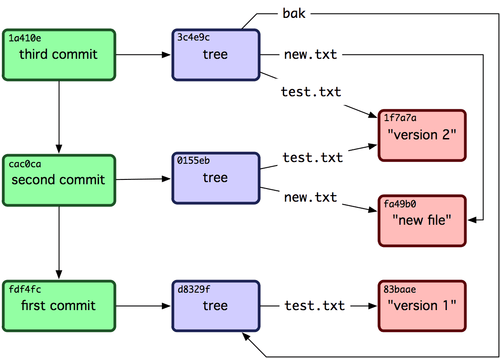
그림 9-3. Git 저장소 내의 모든 개체
개체 저장소
내용과 함께 헤더도 저장한다고 얘기했다. 잠시 Git이 개체를 어떻게 저장하는지부터 살펴보자. "what is up, doc?"이라는 문자열을 가지고 대화형 Ruby 쉘 irb 명령어로 흉내 내 보자:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"
Git은 개체의 타입을 시작으로 헤더를 만든다. 그다음에 공백 문자 하나, 내용의 크기, 마지막에 널 문자를 추가한다:
>> header = "blob #{content.length}\0"
=> "blob 16\000"
Git은 헤더와 원래 내용을 합쳐서 SHA-1 체크섬을 계산한다. Ruby에서도 require로 SHA1 라이브러리를 가져다가 흉내 낼 수 있다. require로 라이브러리를 포함하고 나서 Digest::SHA1.hexdigest()를 호출한다:
>> store = header + content
=> "blob 16\000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
Git은 또 zlib으로 내용을 압축한다. Ruby에도 zlib 라이브러리가 있으니 Ruby에서도 할 수 있다. 라이브러리를 포함하고 Zlib::Deflate.deflate()를 호출한다:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"
마지막으로 zlib으로 압축한 내용을 개체로 저장한다. SHA-1 값 중에서 맨 앞에 있는 두 자를 가져다 하위 디렉토리 이름으로 사용하고 나머지 38자를 그 디렉토리 안에 있는 파일이름으로 사용한다. Ruby에서는 FileUtils.mkdir_p()로 하위 디렉토리의 존재를 보장하고 나서 File.open()으로 파일을 연다. 그리고 그 파일에 zlib으로 압축한 내용을 write() 함수로 저장한다.
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32
다 됐다. 이제 Git Blob 개체를 손으로 만들었다. Git 개체는 모두 이 방식으로 저장하며 단지 종류만 다르다. 헤더가 blob이 아니라 그냥 commit이나 tree로 시작하게 되는 것뿐이다. Blob 개체는 여기서 보여준 것과 거의 같지만 커밋이 개체나 Tree 개체는 각기 다른 형식을 사용한다.