브랜치란 무엇인가?
Git이 브랜치하는 과정을 이해하려면 우선 Git이 데이터를 어떻게 저장하는지 알아야 한다. Git은 데이터를 Change Set이나 변경사항(Diff)으로 기록하지 않고 일련의 스냅샷으로 기록한다는 것을 1장에서 보여줬다.
커밋하면 Git은 현 Staging Area에 있는 데이터의 스냅샷에 대한 포인터, 저자나 커밋 메시지 같은 메타데이터, 이전 커밋에 대한 포인터 등을 포함하는 커밋 개체(커밋 Object)를 저장한다. 이전 커밋 포인터가 있어서 현재 커밋이 무엇을 기준으로 바뀌었는지를 알 수 있다. 최초 커밋을 제외한 나머지 커밋은 이전 커밋 포인터가 적어도 하나씩 있고 브랜치를 합친 Merge 커밋 같은 경우에는 이전 커밋 포인터가 여러 개 있다.
예제를 보자. 파일이 3개 있는 디렉토리가 하나 있고 이 파일을 Staging Area에 저장하고 커밋해 보자. 파일을 Stage하면 Git 저장소에 파일을 저장하고(Git은 이것을 Blob이라고 부른다) Staging Area에 해당 파일의 체크섬을 저장한다(1장에서 살펴본 SHA-1을 사용한다).
$ git add README test.rb LICENSE
$ git commit -m 'initial commit of my project'
'git commit'으로 커밋하면 먼저 루트 디렉토리와 각 하위 디렉토리의 트리 개체를 체크섬과 함께 저장소에 저장한다. 그다음에 커밋 개체를 만들고 메타데이터와 루트 디렉토리 트리 개체를 가리키는 포인터 정보를 커밋 개체에 넣어 저장한다. 그래서 필요하면 언제든지 스냅샷을 다시 만들 수 있다.
이 작업을 마치고 나면 Git 저장소에는 다섯 개의 데이터 개체가 생긴다. 각 파일에 대한 Blob 세 개, 파일과 디렉토리 구조가 들어 있는 트리 개체 하나, 메타데이터와 루트 트리를 가리키는 포인터가 담긴 커밋 개체 하나이다. 이것을 그림으로 그리면 그림 3-1과 같다.
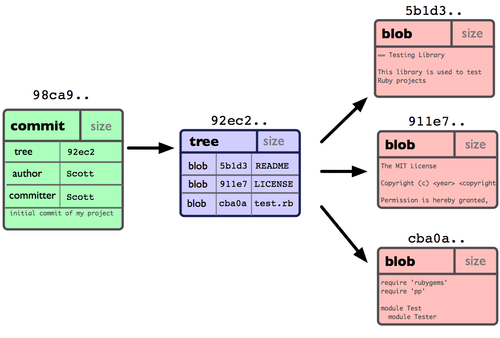
그림 3-1. 저장소의 커밋 데이터
다시 파일을 수정하고 커밋하면 이전 커밋이 무엇인지도 저장한다. 커밋을 두 번 더 하면 그림 3-2과 같이 저장된다.
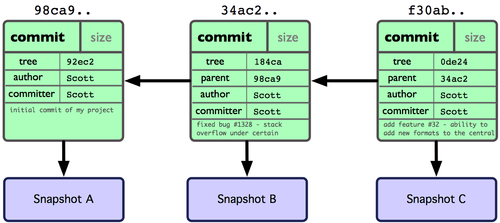
그림 3-2. Git 커밋의 개체 데이터
Git의 브랜치는 커밋 사이를 가볍게 이동할 수 있는 어떤 포인터 같은 것이다. 기본적으로 Git은 master 브랜치를 만든다. 최초로 커밋하면 Git은 master라는 이름의 브랜치를 만들어서 자동으로 가장 마지막 커밋을 가리키게 한다.
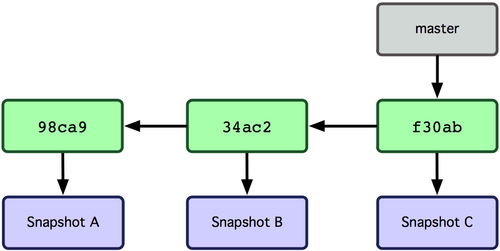
그림 3-3. 가장 최근 커밋 정보를 가리키는 브랜치
브랜치를 하나 새로 만들면 어떨까? 브랜치를 하나 만들어서 놀자. 다음과 같이 git branch 명령으로 testing 브랜치를 만든다.
$ git branch testing
새로 만든 브랜치도 지금 작업하고 있던 마지막 커밋을 가리킨다(그림 3-4).
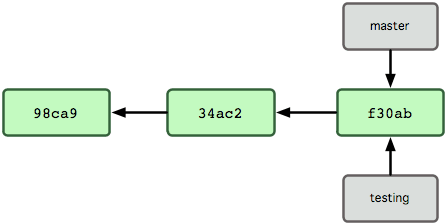
그림 3-4. 커밋 개체를 가리키는 두 브랜치
지금 작업 중인 브랜치가 무엇인지 Git은 어떻게 파악할까? 다른 버전 관리 시스템과는 달리 Git은 'HEAD'라는 특수한 포인터가 있다. 이 포인터는 지금 작업하는 로컬 브랜치를 가리킨다. 브랜치를 새로 만들었지만, Git은 아직 master 브랜치를 가리키고 있다. git branch 명령은 브랜치를 만들기만 하고 브랜치를 옮기지 않는다.
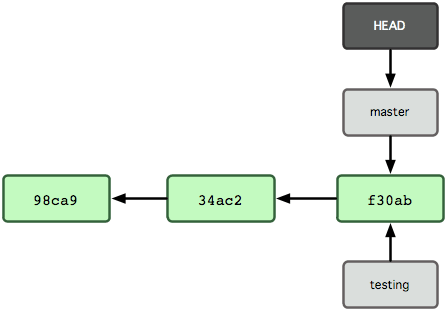
그림 3-5. HEAD는 현재 작업 중인 브랜치를 가리킴
git checkout 명령으로 새로 만든 브랜치로 이동할 수 있다. testing 브랜치로 이동하려면 다음과 같이 한다:
$ git checkout testing
이렇게 하면 HEAD는 testing 브랜치를 가리킨다.
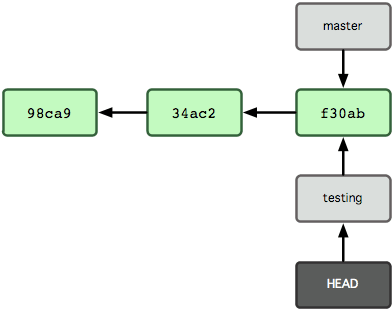
그림 3-6. HEAD는 옮겨간 다른 브랜치를 가리킨다
자, 이제 핵심이 보일 거다! 커밋을 새로 한 번 해보면:
$ vim test.rb
$ git commit -a -m 'made a change'
결과는 그림 3-7과 같다.
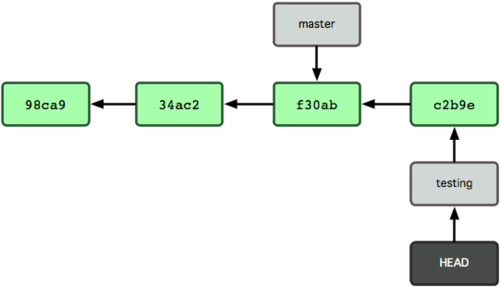
그림 3-7. HEAD가 가리키는 testing 브랜치가 새 커밋을 가리킨다
이 부분이 흥미롭다. 새로 커밋해서 testing 브랜치는 앞으로 이동했다. 하지만, master 브랜치는 여전히 이전 커밋을 가리킨다. master 브랜치로 되돌아가면:
$ git checkout master
결과는 그림 3-8과 같다.
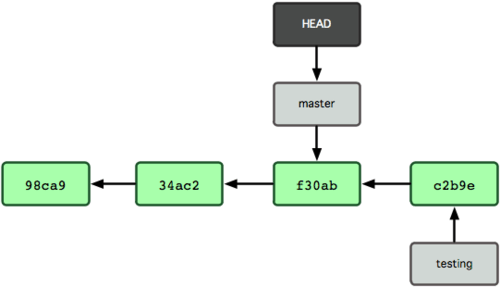
그림 3-8. HEAD가 Checkout한 브랜치로 이동함
방금 실행한 명령이 한 일은 두 가지다. master 브랜치가 가리키는 커밋을 HEAD가 가리키게 하고 워킹 디렉토리의 파일도 그 시점으로 되돌려 놓았다. 앞으로 커밋을 하면 다른 브랜치의 작업들과 별개로 진행되기 때문에 testing 브랜치에서 임시로 작업하고 원래 master 브랜치로 돌아와서 하던 일을 계속할 수 있다.
파일을 수정하고 다시 커밋을 해보자:
$ vim test.rb
$ git commit -a -m 'made other changes'
프로젝트 히스토리는 분리돼 진행한다(그림 3-9). 우리는 브랜치를 하나 만들어 그 브랜치에서 일을 좀 하고, 다시 원래 브랜치로 되돌아와서 다른 일을 했다. 두 작업 내용은 서로 독립적으로 각 브랜치에 존재한다. 커밋 사이를 자유롭게 이동하다가 때가 되면 두 브랜치를 Merge한다. 간단히 branch와 checkout 명령을 써서 말이다.
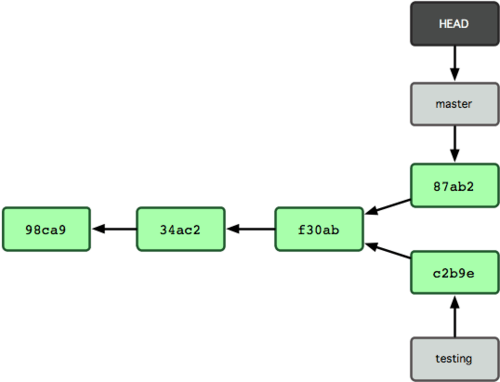
그림 3-9. 브랜치 히스토리가 서로 독립적임
실제로 Git의 브랜치는 어떤 한 커밋을 가리키는 40글자의 SHA-1 체크섬 파일에 불과하기 때문에 만들기도 쉽고 지우기도 쉽다. 새로 브랜치를 하나 만드는 것은 41바이트 크기의 파일을(40자와 줄 바꿈 문자) 하나 만드는 것에 불과하다.
브랜치를 만들어야 하면 프로젝트를 통째로 복사해야 하는 다른 버전 관리 도구와 Git의 차이는 극명하다. 통째로 복사하는 작업은 프로젝트 크기에 따라 다르겠지만 수십 초에서 수십 분까지 걸린다. 그에 비해 Git은 순식간이다. 게다가 커밋을 할 때마다 이전 커밋의 정보를 저장하기 때문에 Merge할 때 어디서부터(Merge Base) 합쳐야 하는지 안다. 이런 특징은 개발자들이 수시로 브랜치를 만들어 사용하게 한다.
이제 왜 그렇게 브랜치를 수시로 만들고 사용해야 하는지 알아보자.