Wat is een branch
Om de manier waarop Git brancht echt te begrijpen, moeten we een stap terug doen en onderzoeken hoe Git zijn gegevens opslaat. Zoals je je misschien herinnert van Hoofdstuk 1, slaat Git zijn gegevens niet op als een reeks van wijzigingen of delta's, maar in plaats daarvan als een serie snapshots.
Als je in Git commit, dan slaat Git een commit object op dat een verwijzing bevat naar het snapshot van de inhoud die je gestaged hebt, de auteur- en bericht-metagegevens, en nul of meer verwijzingen naar de commit of commits die de directe ouders van deze commit waren: nul ouders voor de eerste commit, één ouder voor een normale commit, en meerdere ouders voor een commit die het resultaat is van een merge van twee of meer branches.
Om dit te visualiseren, gaan we aannemen dat je een directory hebt met drie bestanden, en je staget en commit ze allemaal. Je gaat de bestanden stagen waardoor ze allemaal een checksum krijgen (de SHA-1 hash waar we het in Hoofdstuk 1 over hadden), bewaart die versie van het bestand in het Git repository (Git noemt ze blobs), en voegt die checksum toe aan de staging area:
$ git add README test.rb LICENSE
$ git commit -m 'initial commit of my project'
Als je de commit aanmaakt door git commit uit te voeren zal Git iedere directory in het project van een checksum voorzien en slaat ze als boomstructuur (tree) objecten in de Git repository op. Daarna creëert Git een commit object dat de metagegevens bevat en een verwijzing naar de hoofd-tree-object van het project zodat Git deze snapshot opnieuw kan oproepen als dat nodig is.
Je Git repository bevat nu vijf objecten: een blob voor de inhoud van ieder van de drie bestanden, een tree die de inhoud van de directory weergeeft en specificeert welke bestandsnamen opgeslagen zijn als welke blobs, en een commit met de verwijzing naar die hoofd-tree en alle commit-metagegevens. Conceptueel zien de gegevens in je Git repository eruit zoals in Figuur 3-1.
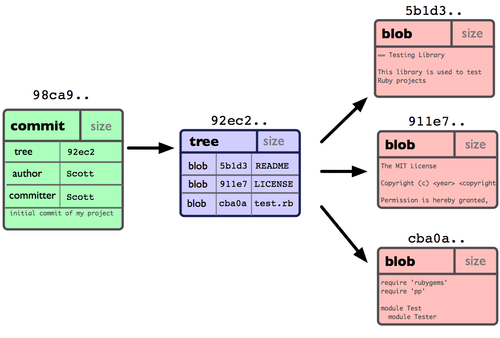
Figuur 3-1. Repository gegevens van een enkele commit.
Als je wat wijzigingen maakt en nogmaals commit, dan slaat de volgende commit een verwijzing op naar de commit die er direct aan vooraf ging. Na nog eens twee commits, zal je historie er ongeveer uit zien als Figuur 3-2.
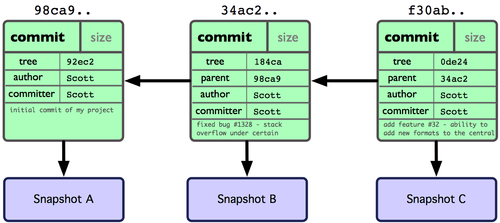
Figuur 3-2. Git objectgegevens voor meerdere commits.
Een branch in Git is simpelweg een lichtgewicht verplaatsbare verwijzing naar een van deze commits. De standaard branch-naam in Git is master. Als je initieel commits maakt, dan krijg je een master-branch die wijst naar de laatste commit die je gemaakt hebt. Iedere keer als je commit, beweegt het automatisch vooruit.
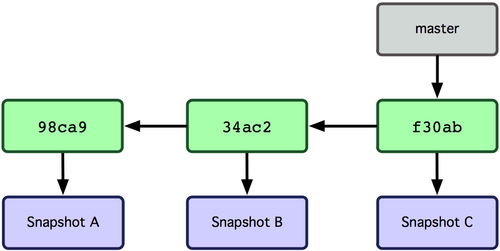
Figuur 3-3. Branch wijzend in de commit gegevens historie.
Wat gebeurt er als je een nieuwe branch maakt? Door dat te doen wordt een nieuwe verwijzing voor je aangemaakt die je dan kunt verplaatsen. Laten we zeggen dat je een nieuwe branch genaamd testing maakt. Je doet dit met het git branch commando:
$ git branch testing
Dit maakt een nieuwe verwijzing naar dezelfde commit waar je nu op zit (zie Figuur 3-4).
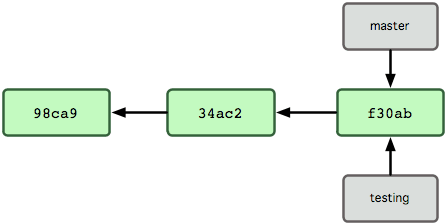
Figuur 3-4. Meerdere branches wijzend naar de commit-gegevenshistorie.
Hoe weet Git op welke branch je nu zit? Het houdt een speciale verwijzing bij genaamd HEAD. Let op dat dit heel anders is dan het concept van HEAD in andere VCS's waar je misschien gewend aan bent, zoals Subversion of CVS. In Git is dit een verwijzing naar de lokale branch waar je nu op zit. In dit geval zit je nog steeds op master. Het git branch-commando heeft alleen een nieuwe branch aangemaakt - we zijn nog niet overgeschakeld naar die branch (zie Figuur 3-5).
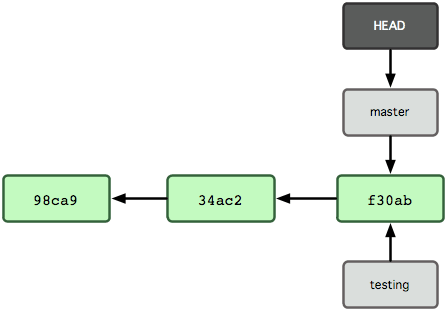
Figuur 3-5. HEAD-bestand wijzend naar de branch waar je op zit.
Om over te schakelen naar een bestaande branch, voer je het git checkout commando uit. Laten we eens overschakelen naar de nieuwe testing branch:
$ git checkout testing
Dit verplaatst HEAD zodat het wijst naar de testing branch (zie Figuur 3-6).
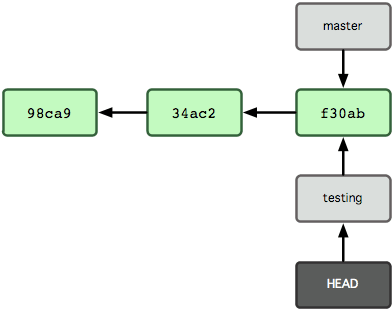
Figuur 3-6. HEAD wijst naar een andere branch als je omschakelt.
Wat is hier het belang van? Wel, laten we eens een andere commit doen:
$ vim test.rb
$ git commit -a -m 'made a change'
Figuur 3-7 toont het resultaat.
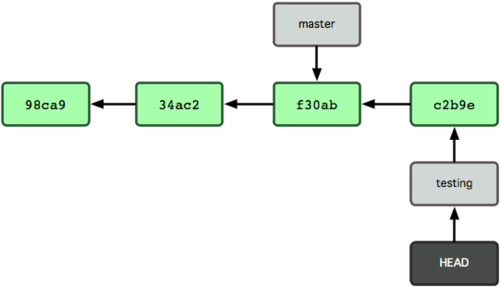
Figuur 3-7. De branch waar HEAD naar wijst gaat vooruit met iedere commit.
Dit is interessant, omdat je testing branch nu vooruit is gegaan, maar je master branch nog steeds wijst naar de commit waar je op was toen je git checkout uitvoerde voor het overschakelen. Laten we eens terugschakelen naar de master branch:
$ git checkout master
Figuur 3-8 toont het resultaat.
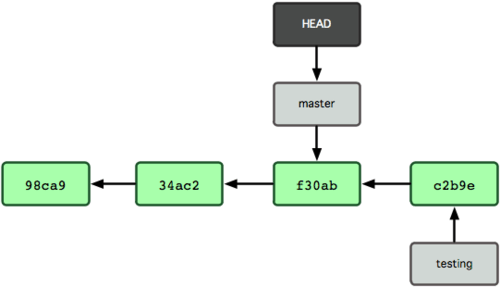
Figuur 3-8. HEAD verschuift naar een andere branch bij een checkout.
Dat commando heeft twee dingen gedaan. Het verplaatste de HEAD verwijzing terug naar de master branch, en het draaide de bestanden in je werkdirectory terug naar de snapshot waar die master naar wijst. Dit betekent ook dat de wijzigingen die je vanaf dit punt maakt uiteen zullen gaan lopen met een oudere versie van het project. In essentie betekent het dat het werk dat je in je testing branch hebt gedaan tijdelijk wordt teruggedraaid, zodat je een andere richting op kunt gaan.
Laten we een paar wijzigingen maken en nog eens committen:
$ vim test.rb
$ git commit -a -m 'made other changes'
Nu is je projecthistorie uiteengelopen (zie Figuur 3-9). Je hebt een branch gemaakt en bent er naartoe overgeschakeld, hebt er wat werk op gedaan, en bent toen teruggeschakeld naar je hoofd-branch en hebt nog wat ander werk gedaan. Al die veranderingen zijn geïsoleerd van elkaar in aparte branches: je kunt heen en weer schakelen tussen de branches en ze mergen als je klaar bent. En je hebt dat alles gedaan met eenvoudige branch en checkout commando's.
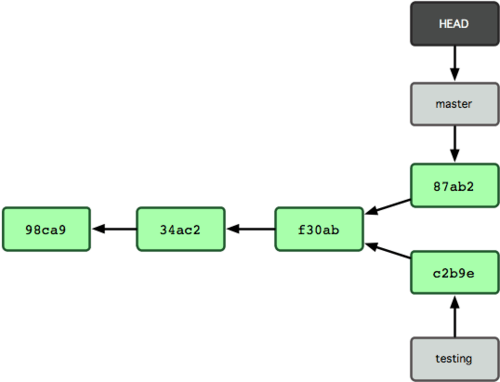
Figuur 3-9. De branch-histories zijn uiteen gaan lopen.
Omdat een branch in Git in feite een eenvoudig bestand is dat de 40 karakter lange SHA-1 checksum van de commit bevat waar het naar wijst, zijn branches goedkoop om te maken en weer weg te gooien. Een nieuwe branch aanmaken is zo snel en eenvoudig als 41 bytes naar een bestand schrijven (40 karakters en een harde return).
Dit is in scherp contrast met de wijze waarop de meeste VCS applicaties branchen, wat vaak het kopiëren van alle projectbestanden naar een tweede map inhoudt. Dit kan enkele seconden of zelfs minuten duren, afhankelijk van de grootte van het project, daarentegen is het in Git altijd vrijwel meteen klaar. En omdat we de ouders opslaan terwijl we committen, wordt het vinden van een goed punt dat kan dienen als basis voor het mergen automatisch voor ons gedaan en is dat over het algemeen eenvoudig om te doen. Deze eigenschappen moedigen ontwikkelaars aan om vaak branches aan te maken en te gebruiken.
Laten we eens kijken waarom je dat zou moeten doen.