Revisie selectie
Git stelt je in staat om specifieke commits of een serie commits op diverse manieren te specificeren. Ze zijn niet meteen voor de hand liggend, maar behulpzaam om te weten.
Enkele revisies
Natuurlijk kun je naar een commit refereren met de SHA-1 hash die het toegekend is, maar er zijn ook meer mensvriendelijke manieren om naar een commit te refereren. In deze paragraaf worden diverse manieren getoond waarop je naar een enkele commit kunt refereren.
Korte SHA
Git is slim genoeg om uit te vinden welke commit je bedoelde te typen als je het de eerste paar karakters geeft, zolang je gedeeltelijke SHA-1 maar minstens vier karakters lang en ondubbelzinnig is; dat wil zeggen dat slechts één object in de huidige repository begint met die gedeeltelijke SHA-1.
Bijvoorbeeld, stel dat je om een specifieke commit te zien een git log commando uitvoert en de commit identificeert waarin je een bepaalde functionaliteit hebt toegevoegd:
$ git log
commit 734713bc047d87bf7eac9674765ae793478c50d3
Author: Scott Chacon <[email protected]>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <[email protected]>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <[email protected]>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
Kies in dit geval 1c002dd..... Als je op die commit git show uitvoert, dan zijn de volgende commando's gelijkwaardig (aangenomen dat de kortere versies ondubbelzinnig zijn):
$ git show 1c002dd4b536e7479fe34593e72e6c6c1819e53b
$ git show 1c002dd4b536e7479f
$ git show 1c002d
Git kan met een korte unieke afkorting van een SHA-1 waarde uit de voeten. Als je --abbrev-commit meegeeft aan het git log commando, dan zal de output kortere waarden gebruiken maar ze uniek houden; het gebruikt standaard zeven karakters maar maakt ze langer indien nodig om de SHA-1 ondubbelzinnig te houden:
$ git log --abbrev-commit --pretty=oneline
ca82a6d changed the version number
085bb3b removed unnecessary test code
a11bef0 first commit
Over het algemeen zijn acht tot tien karakters meer dan voldoende om binnen een project uniek te zijn. Een van de grootste Git projecten, de Linux kernel, begint 12 karakters van de mogelijke 40 nodig te hebben om uniek te blijven.
EEN KORTE NOTITIE OVER SHA-1
Veel mensen beginnen bezorgd te raken dat ze op een bepaald moment door puur toeval, twee objecten in hun repository hebben die naar dezelfde SHA-1 waarde hashen. Wat dan?
Mocht je een object committen dat hashed naar dezelfde SHA-1 waarde als een vorig object in je repository, dan zal Git het vorige reeds aanwezige object in je Git database zien en aannemen dat het al geschreven was. Als je op een bepaald moment dat object opnieuw probeert uit te checken, dan zal je altijd de gegevens van het eerste object krijgen.
Maar wat je moet beseffen is hoe vreselijk onwaarschijnlijk dit scenario is. De SHA-1 waarde is 20 bytes, oftewel 160 bits. Het aantal benodigde random gehashte objecten om een 50% waarschijnlijkheid van een botsing te garanderen is ongeveer 2^80 (de formule om botsingswaarschijnlijkheid te bepalen is p = (n(n-1)/2) * (1/2^160)). 2^80 is 1.2 x 10^24 of 1 miljoen miljard miljard. Dat is 1.200 keer het aantal zandkorrels op aarde.
Hier is een voorbeeld om je een idee te geven wat er voor nodig is om een SHA-1 botsing te krijgen. Als alle 6.5 miljard mensen op aarde zouden programmeren, en iedere seconde zou ieder van hen code genereren die gelijk was aan de hele Linux kernel-geschiedenis (1 miljoen Git objecten) en dat in één gigantische Git repository pushen, dan zou het vijf jaar duren voordat die repository genoeg objecten zou bevatten om een 50% waarschijnlijkheid van één enkele SHA-1 object botsing te krijgen. De kans is groter dat elk lid van je programmeerteam zal worden aangevallen en gedood door wolven bij ongerelateerde incidenten op dezelfde avond.
Branch referenties
De meest eenvoudige manier om een commit te specificeren heeft als voorwaarde dat je er een branchreferentie naar hebt wijzen. Dan kun je een branchnaam in ieder Git commando gebruiken dat een commitobject of SHA-1 waarde verwacht. Bijvoorbeeld, als je het laatste commitobject op een branch wil tonen, dan zijn de volgende commando's gelijkwaardig, aangenomen dat de topic1 branch naar ca82a6d wijst:
$ git show ca82a6dff817ec66f44342007202690a93763949
$ git show topic1
Als je wilt zien naar welke specifieke SHA een branch wijst, of als je wil zien wat ieder van deze voorbeelden in termen van SHA's voorstellen, dan kun je een Git sanitaire voorzieningen (plumbing) tool genaamd rev-parse gebruiken. Je kunt in Hoofdstuk 9 kijken voor meer informatie over plumbingtools, eigenlijk is rev-parse er voor low-level operaties en is niet ontworpen voor dagelijks gebruik. Maar het kan behulpzaam zijn op momenten dat je moet zien wat er echt aan de hand is. Hier kun je rev-parse uitvoeren op je branch.
$ git rev-parse topic1
ca82a6dff817ec66f44342007202690a93763949
RefLog afkortingen
Een van de dingen die Git in de achtergrond doet terwijl jij lekker zit te werken is een reflog bijhouden: een log waarin is vastgelegd naar welke referenties de HEAD en de branches de laatste paar maanden hebben gewezen.
Je kunt je reflog zien door git reflog te gebruiken:
$ git reflog
734713b... HEAD@{0}: commit: fixed refs handling, added gc auto, updated
d921970... HEAD@{1}: merge phedders/rdocs: Merge made by recursive.
1c002dd... HEAD@{2}: commit: added some blame and merge stuff
1c36188... HEAD@{3}: rebase -i (squash): updating HEAD
95df984... HEAD@{4}: commit: # This is a combination of two commits.
1c36188... HEAD@{5}: rebase -i (squash): updating HEAD
7e05da5... HEAD@{6}: rebase -i (pick): updating HEAD
Iedere keer als de punt van je branch om een of andere reden is gewijzigd, dan bewaart Git die informatie voor je in deze tijdelijke geschiedenis. En je kunt ook oudere commits met deze gegevens specificeren. Als je de vijfde voorgaande waarde van de HEAD van je repository wilt zien, dan kun je de @{n} referentie gebruiken, die je in de reflog output kunt zien:
$ git show HEAD@{5}
Je kunt deze syntax ook gebruiken om te zien waar een branch een bepaalde tijd geleden was. Bijvoorbeeld, om te zien waar je master branch gisteren was, kun je dit typen
$ git show master@{yesterday}
Dat laat je zien waar de punt van de branch gisteren was. Deze techniek werkt alleen voor gegevens die nog steeds in je reflog staan, dus je kunt het niet gebruiken om te kijken naar commits die ouder zijn dan een paar maanden.
Om reflog informatie te zien, in hetzelfde formaat als de git log output, kun je git log -g uitvoeren:
$ git log -g master
commit 734713bc047d87bf7eac9674765ae793478c50d3
Reflog: master@{0} (Scott Chacon <[email protected]>)
Reflog message: commit: fixed refs handling, added gc auto, updated
Author: Scott Chacon <[email protected]>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Reflog: master@{1} (Scott Chacon <[email protected]>)
Reflog message: merge phedders/rdocs: Merge made by recursive.
Author: Scott Chacon <[email protected]>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Het is belangrijk om op te merken dat deze informatie strikt lokaal is - het is een log van wat jij hebt gedaan in jouw repository. De referenties zullen niet hetzelfde zijn in de kopie van de repository die iemand anders gemaakt heeft; en meteen nadat je een eerste clone van een repository hebt gemaakt heb je een lege reflog, omdat er nog geen activiteit is geweest in je repository. git show HEAD@{2.months.ago} uitvoeren werkt alleen als je het project minstens twee maanden geleden gecloned hebt, als je het vijf minuten geleden gecloned hebt krijg je geen resultaten.
Voorouder referenties
De andere veelgebruikte manier om een commit te specificeren is via zijn voorouders. Als je een ^ aan het einde van een referentie zet, zal Git hieruit herleiden dat het de ouder van die commit betekent.
Stel dat je naar de geschiedenis van je project kijkt:
$ git log --pretty=format:'%h %s' --graph
* 734713b fixed refs handling, added gc auto, updated tests
* d921970 Merge commit 'phedders/rdocs'
|\
| * 35cfb2b Some rdoc changes
* | 1c002dd added some blame and merge stuff
|/
* 1c36188 ignore *.gem
* 9b29157 add open3_detach to gemspec file list
Dan zie je de vorige commit door HEAD^ te specificeren, wat "de ouder van HEAD" betekent:
$ git show HEAD^
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <[email protected]>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Je kunt ook een getal na de ^ zetten, bijvoorbeeld d921970^2 betekent "de tweede ouder van d921970." Deze syntax is alleen nuttig voor merge commits, omdat die meer dan één ouder hebben. De eerste ouder is de branch waar jij op was toen je mergede, en de andere is de commit op de branch die je gemerged hebt:
$ git show d921970^
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <[email protected]>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
$ git show d921970^2
commit 35cfb2b795a55793d7cc56a6cc2060b4bb732548
Author: Paul Hedderly <[email protected]>
Date: Wed Dec 10 22:22:03 2008 +0000
Some rdoc changes
De andere manier om voorouders mee te specificeren is de ~. Dit refereert ook naar de eerste ouder, dus HEAD~ en HEAD^ zijn gelijk. Het verschil wordt pas duidelijk als je een getal specificeert. HEAD~2 betekent "de eerste ouder van de eerste ouder", of "de grootouder" - het doorloopt de eerste ouders het aantal keren dat je specificeert. Bijvoorbeeld, in de geschiedenis die eerder getoond werd, zou HEAD~3 het volgende resultaat geven
$ git show HEAD~3
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <[email protected]>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
Dit kan ook geschreven worden als HEAD^^^ wat, nogmaals, de eerste ouder van de eerste ouder van de eerste ouder is:
$ git show HEAD^^^
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <[email protected]>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
Je kunt deze syntaxen combineren: je kunt de tweede ouder van de vorige referentie krijgen (aangenomen dat het een merge commit was) door HEAD~3^2 te gebruiken, enzovoort.
Commit reeksen
Nu je individuele commits kunt specificeren, laten we zien hoe je reeksen van commits kunt specificeren. Dit is vooral erg nuttig bij het beheren van je branches - als je veel branches hebt, kan je reeks-specificaties gebruiken om vragen te beantwoorden als: "Wat voor werk zit er op deze branch dat ik nog niet in mijn hoofdbranch gemerged heb?"
Dubbel-punt
De meest voorkomende reeks specificatie is de dubbel-punt syntax. Eigenlijk vraag je hiermee aan Git een reeks commits op te zoeken, die bereikbaar zijn van de ene commit maar niet vanuit een ander. Bijvoorbeeld, stel dat je een commit-geschiedenis hebt die eruit ziet zoals in Figuur 6-1.
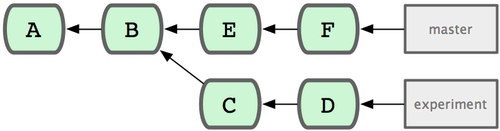
Figuur 6-1. Voorbeeldgeschiedenis voor reeks-selectie.
Je wilt zien wat er in je experimentele branch zit dat nog niet in je hoofdbranch gemerged is. Je kunt Git vragen om een log te tonen van alleen die commits met master..experiment, wat zoveel betekent als "alle commits die bereikbaar zijn voor experiment, die niet bereikbaar zijn voor master". Om de voorbeelden kort en duidelijk te houden zal ik de letters van de commitobjecten in het diagram gebruiken in plaats van de echte log output, in de volgorde waarin ze getoond zouden worden:
$ git log master..experiment
D
C
Als je echter het tegenovergestelde wilt zien - alle commits in master die niet in experiment zitten - dan moet je de branchnamen omdraaien. experiment..master toont je alles in master wat niet bereikbaar is vanuit experiment:
$ git log experiment..master
F
E
Dit is handig als je de experiment branch up to date wilt houden en alvast wilt zien wat je op het punt staat te mergen. Een ander veel voorkomend gebruik van deze syntax is zien wat je op het punt staat naar een remote de pushen:
$ git log origin/master..HEAD
Dit commando toont je alle commits in je huidige branch, die niet in de master branch op de remote origin zitten. Als je een git push uitvoert, en je huidige branch volgt de origin/master, dan zijn de commits die getoond worden door git log origin/master..HEAD de commits die verstuurd zullen worden naar de server.
Je kunt ook één kant van de syntax weglaten om Git de HEAD laten aannemen. Bijvoorbeeld, je krijgt dezelfde resultaten als in het vorige voorbeeld door git log origin/master.. te typen - Git vult HEAD in als er één kant ontbreekt.
Dubbele punten
De syntax met de dubbel-punt is makkelijk als een afkorting, maar misschien wil je meer dan twee branches specificeren om je revisie aan te geven, zoals het zien welke commits in één van de branches in een reeks zitten, die nog niet in de branch zitten waar je nu op werkt. Git laat je dit doen door of het ^ karakter of --not, te gebruiken voor iedere referentie waarvan je de bereikbare commits niet wilt zien. Dus deze drie commando's zijn gelijk:
$ git log refA..refB
$ git log ^refA refB
$ git log refB --not refA
Dit is prettig omdat met deze syntax je meer dan twee referenties in je vraag kunt specificeren, wat je niet met de dubbel punt syntax kan doen. Bijvoorbeeld, als je alle commits wilt zien die bereikbaar zijn vanuit refA of refB, maar niet vanuit refC, dan kun je één van deze intypen:
$ git log refA refB ^refC
$ git log refA refB --not refC
Dit zorgt voor een erg krachtig revisie vraagsysteem dat je kan helpen om uit te zoeken wat in je branches zit.
Drievoudige punt
De laatste veelgebruikte reeks-selectie syntax is de drievoudige punt syntax, wat alle commits specificeert die bereikbaar zijn door één van de twee referenties, maar niet door allebei. Kijk nog eens naar de voorbeeld commitgeschiedenis in Figuur 6-1.
Als je wilt zien wat in je master of in je experiment zit, maar geen gedeelde referenties, dan kun je dit uitvoeren
$ git log master...experiment
F
E
D
C
Nogmaals, dit geeft je normale log output, maar toont je alleen de commit-informatie voor deze vier commits, getoond in de traditionele volgorde van committijdstip.
Een veelgebruikte optie bij het log command in dit geval is --left-right, wat je laat zien aan welke kant van de reeks elke commit zit. Dit helpt de data bruikbaarder te maken:
$ git log --left-right master...experiment
< F
< E
> D
> C
Met deze tools, kun je Git eenvoudiger laten weten welke commit of commits je wilt inspecteren.