Git attributen
Een aantal van deze instellingen kan ook gedaan worden voor een pad, zodat Git die instellingen alleen toepast voor een subdirectory of subset van bestanden. Deze pad-specifieke instellingen worden Git attributen genoemd en worden in een .gitattribute bestand in een van je directories gezet (normaliter in de hoofddirectory van je project) of in het .git/info/attributes bestand als je niet wilt dat het attributes bestand gecommit wordt met je project.
Door attributen te gebruiken kun je dingen doen als het specificeren van aparte merge strategieën voor individuele bestanden of directories in je project, Git vertellen hoe niet-tekst bestanden moeten worden gediff'ed, of Git inhoud laten filteren voordat je het in- of uitcheckt van Git. In deze paragraaf zal je iets leren over de attributen die je kun instellen op de paden in je Git project en een paar voorbeelden zien hoe je deze eigenschappen in de praktijk gebruikt.
Binaire bestanden
Een leuke truc waarvoor je Git attributen kunt gebruiken is het vertellen aan Git welke bestanden binair zijn (in die gevallen waarin hij het niet zelf kan ontdekken) en Git dan speciale instructies geven hoe die bestanden te behandelen. Bijvoorbeeld, sommige tekstbestanden worden gegenereerd en zijn niet te diff'en, of sommige binaire bestanden kunnen wel gediff'ed worden – je zult zien hoe je Git vertelt welke soort het is.
Binaire bestanden identificeren
Sommige bestanden zien eruit als tekstbestanden, maar moeten toch behandeld worden als binaire gegevens. Bijvoorbeeld, Xcode projecten op de Mac bevatten een bestand dat eindigt in .pbxproj, wat eigenlijk een JSON (javascript gegevens in platte tekst formaat) gegevensset is, dat geschreven wordt naar de schijf door de IDE en waarin je bouw-instellingen enzovoorts opgeslagen zijn. Alhoewel het technisch gezien een tekstbestand is, omdat het volledig ASCII is, zul je het niet als zodanig willen behandelen omdat het eigenlijk een lichtgewicht gegevensbank is – je kunt de inhoud niet mergen als twee mensen het gewijzigd hebben, en diffs zijn over het algemeen niet behulpzaam. Het bestand is bedoeld om gebruikt te worden door een machine. In essentie wil je het behandelen als een binair bestand.
Om Git te vertellen dat hij alle pbxproj bestanden als binaire gegevens moet behandelen, voeg je de volgende regel toe aan je .gitattributes bestand:
*.pbxproj -crlf -diff
Nu zal Git niet proberen om CRLF problemen te corrigeren of repareren; noch zal het proberen een diff te berekenen of te tonen voor de veranderingen in dit bestand als je git show of git diff uitvoert op je project. In de 1.6 serie van Git, kun je ook het ingebouwde macro binary gebruiken die -crlf -diff vervangt:
*.pbxproj binary
Binaire bestanden diff'en
In Git kan je de functionaliteit van Git attributen gebruiken om binaire bestanden uiteindelijk toch te diff'en. Je doet dit door Git te vertellen hoe het de binaire gegevens naar tekst formaat moet omzetten, die dan via de normale diff vergeleken kan worden. Maar de vraag is hoe je de binaire gegevens naar tekst omzet. De beste oplossing is om een tool te vinden die deze conversie van binair naar tekstformaat voor je doet. Helaas kunnen weinig binaire formaten als mens-leesbaar formaat gerepresenteerd worden (probeer maar eens de gegevens van een geluidsfragment om te zetten naar tekst). Als dit het geval is en je bent er niet in geslaagd om een tekst-representatie te krijgen van de inhoud van het bestand, is het vaak relatief eenvoudig om een menselijk leesbare omschrijving van de inhoud of metadata te verkrijgen. Metadata geeft je niet een volledige representatie van de inhoud van het bestand, maar het is in elk geval beter dan niets.
We gaan beide beschreven varianten gebruiken om bruikbare diff's te krijgen voor vaakgebruikte binaire formaten.
Even een terzijde: Er zijn verscheidene binaire formaten met een tekstinhoud waar moeilijk een bruikbare converter voor te vinden is. In die gevallen kan je proberen een tekst uit het bestand extraheren met het strings programma. Sommige van deze bestanden zouden een UTF-16 encoding of andere "codepages" kunnen gebruiken en dan kan strings niets bruikbaars in die bestanden vinden. Resultaten in het verleden geven geen garantie voor de toekomst. Echter strings wordt geleverd bij de meeste Mac en Linux systemen, dus het zou een goede eerste kandidaat zijn om dit te proberen bij veel binaire formaten.
MS Word bestanden
Ten eerste zullen we de beschreven techniek gebruiken om een van de meest ergerlijke problemen in de menselijke geschiedenis op te lossen: Word documenten onder versiebeheer brengen. Iedereen weet dat Word een van de slechtste editors verkrijgbaar is; maar, vreemd genoeg, iedereen gebruikt het. Als je Word documenten in versie beheer wilt krijgen, kan je ze in een Git repostiory gooien en om de zoveel tijd een commit uitvoeren, maar wat voor nut heeft dit? Als je git diff uitvoert, zou je iets als dit zien:
$ git diff
diff --git a/chapter1.doc b/chapter1.doc
index 88839c4..4afcb7c 100644
Binary files a/chapter1.doc and b/chapter1.doc differ
Je kunt niet direct twee versies vergelijken tenzij je ze uitcheckt en handmatig doorneemt, toch? Maar gelukkig kan je dit toch redelijk goed met Git attributen doen. Zet de volgende regel in je .gitattributes bestand:
*.doc diff=word
Dit vertelt Git dat alle bestanden die in het patroon (.doc) passen het "word" filter moeten gebruiken als je een diff probeert te bekijken die wijzigingen bevat. Wat is dat "word" filter eigenlijk? Je moet het zelf opzetten. Hier ga je Git configureren om het catdoc programma te gebruiken, die specifiek geschreven is om tekst uit binaire MS Word documenten te extraheren (je kunt het krijgen op http://www.wagner.pp.ru/~vitus/software/catdoc/), om Word documenten in leesbare tekstbestanden te converteren, en die vervolgens juist diff'en:
$ git config diff.word.textconv catdoc
Dit commando voegt een sectie toe aan je .git/config, wat er ongeveer zo uitziet:
[diff "word"]
textconv = catdoc
Nu weet Git dat wanneer het probeert een diff uit te voeren tussen twee snapshots, en bestandsnamen eindigen op .doc dat het deze bestanden door de "word" filter moet halen, die gedefinieerd is als het catdoc programma. Effectief maakt het twee gewone tekst-gebaseerde versies van je Word bestanden vooraleer te proberen ze met diff te vergelijken.
Hier is een voorbeeld. Ik heb hoofdstuk 1 van dit boek in Git gezet, wat tekst in een paragraaf toegevoegd en daarna het document gesaved. Daarna voerde ik git diff uit om te zien wat er gewijzigd was:
$ git diff
diff --git a/chapter1.doc b/chapter1.doc
index c1c8a0a..b93c9e4 100644
--- a/chapter1.doc
+++ b/chapter1.doc
@@ -128,7 +128,7 @@ and data size)
Since its birth in 2005, Git has evolved and matured to be easy to use
and yet retain these initial qualities. It’s incredibly fast, it’s
very efficient with large projects, and it has an incredible branching
-system for non-linear development.
+system for non-linear development (See Chapter 3).
Git vertelt me succesvol en kort en bondig dat ik de tekst "(See Chapter 3)" heb toegevoegd, wat juist is. Werkt perfect!
OpenDocument tekst bestanden
Dezelfde aanpak die we hebben gebruikt vooro MS Word bestanden (*.doc) kan worden gebruikt bij OpenDocument Tekst bestanden (*.odt) wat gemaakt is door OpenOffice.org.
Voeg de volgende regel toe aan je .gitattributes bestand:
*.odt diff=odt
Zet nu het odt diff filter op in .git/config:
[diff "odt"]
binary = true
textconv = /usr/local/bin/odt-to-txt
OpenDocument bestanden zijn eigenlijk gezipte directories met daarin meerdere bestanden (de inhoud ervan in een XML formaat, stylesheets, plaatjes, etc.). Ze zullen een script moeten schrijven om de inhoud te extraheren en dit terug te geven als platte tekst. Maak een bestand /usr/local/bin/odt-to-txt (het staat je vrij om dit in een andere directory neer te zetten) met de volgende inhoud:
#! /usr/bin/env perl
# Simplistic OpenDocument Text (.odt) to plain text converter.
# Author: Philipp Kempgen
if (! defined($ARGV[0])) {
print STDERR "No filename given!\n";
print STDERR "Usage: $0 filename\n";
exit 1;
}
my $content = '';
open my $fh, '-|', 'unzip', '-qq', '-p', $ARGV[0], 'content.xml' or die $!;
{
local $/ = undef; # slurp mode
$content = <$fh>;
}
close $fh;
$_ = $content;
s/<text:span\b[^>]*>//g; # remove spans
s/<text:h\b[^>]*>/\n\n***** /g; # headers
s/<text:list-item\b[^>]*>\s*<text:p\b[^>]*>/\n -- /g; # list items
s/<text:list\b[^>]*>/\n\n/g; # lists
s/<text:p\b[^>]*>/\n /g; # paragraphs
s/<[^>]+>//g; # remove all XML tags
s/\n{2,}/\n\n/g; # remove multiple blank lines
s/\A\n+//; # remove leading blank lines
print "\n", $_, "\n\n";
En maak het uitvoerbaar
chmod +x /usr/local/bin/odt-to-txt
Nu zal git diff je kunnen vertellen wat er gewijzigd is in .odt bestanden.
Beeldbestanden
Een ander interessant probleem dat je hiermee kunt oplossen is het diff'en van beeldbestanden. Een manier om dit te doen is PNG bestanden door een filter te halen dat de EXIF informatie eruit peutert - dat is metadata die wordt opgeslagen bij de meeste beeldbestand formaten. Als je het exiftool programma downloadt en installeert, kan je dit gebruiken om je plaatjes naar tekst over de metadata om te zetten, zodat de diff op z'n minst een tekstuele representatie van eventuele wijzigingen laat zien:
$ echo '*.png diff=exif' >> .gitattributes
$ git config diff.exif.textconv exiftool
Als je een plaatje in je project vervangt en git diff uitvoert, dan zie je zoiets als dit:
diff --git a/image.png b/image.png
index 88839c4..4afcb7c 100644
--- a/image.png
+++ b/image.png
@@ -1,12 +1,12 @@
ExifTool Version Number : 7.74
-File Size : 70 kB
-File Modification Date/Time : 2009:04:21 07:02:45-07:00
+File Size : 94 kB
+File Modification Date/Time : 2009:04:21 07:02:43-07:00
File Type : PNG
MIME Type : image/png
-Image Width : 1058
-Image Height : 889
+Image Width : 1056
+Image Height : 827
Bit Depth : 8
Color Type : RGB with Alpha
Je kunt eenvoudig zien dat zowel de bestandsgrootte als de beeld dimensies gewijzigd zijn.
Keyword expansie
Keyword expansie zoals in SVN of CVS gebruikt wordt, wordt vaak gevraagd door ontwikkelaars die gewend zijn aan die systemen. Het grote probleem in Git is dat je een bestand niet mag wijzigen met informatie over de commit nadat je het gecommit hebt, omdat Git eerst de checksum van het bestand maakt. Maar, je kunt tekst in een bestand injecteren zodra het uitgechecked wordt en dit weer verwijderen voordat het aan een commit toegevoegd wordt. Met Git attributen zijn er twee manieren om dit te doen.
Als eerste kun je de SHA-1 checksum van een blob automatisch in een $Id$ veld in het bestand stoppen. Als je dit attribuut in een bestand of aantal bestanden zet, dan zal Git de volgende keer dat je die branch uitcheckt dat veld vervangen met de SHA-1 van de blob. Het is belangrijk om op te merken dat het niet de SHA van de commit is, maar van de blob zelf:
$ echo '*.txt ident' >> .gitattributes
$ echo '$Id$' > test.txt
De volgende keer dat je dit bestand uitcheckt, injecteert Git de SHA van de blob:
$ rm text.txt
$ git checkout -- text.txt
$ cat test.txt
$Id: 42812b7653c7b88933f8a9d6cad0ca16714b9bb3 $
Echter dit resultaat heeft slechts een beperkte nut. Als je sleutelwoord vervanging (keyword substitution) in CVS of Subversion gebruikt hebt, kun je een datumstempel toevoegen – de SHA is niet zo bruikbaar, omdat het vrij willekeurig is en je kunt niet zeggen of de ene SHA ouder of nieuwer is dan de andere.
Je kunt echter je eigen filters voor het doen van vervanging bij commit/checkout schrijven. Dit zijn de "kuis" ("clean") en "besmeer" ("smudge") filters. In het .gitattributes bestand kan je voor bepaalde paden een filter instellen en dan scripts instellen die bestanden bewerkt vlak voordat ze uitgechecked worden ("smudge", zie Figuur 7-2) en vlak voordat ze gecommit worden ("clean", zie Figuur 7-3). De filters kunnen ingesteld worden om allerlei leuke dingen doen.
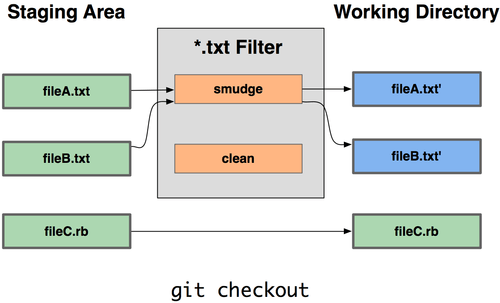
Figuur 7-2. Het “smudge” filter wordt bij checkout uitgevoerd.
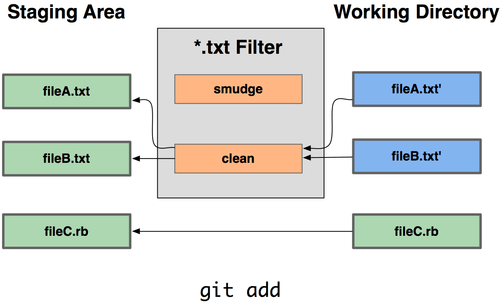
Figuur 7-3. Het “clean” filter wordt uitgevoerd zodra bestanden worden gestaged.
De originele commit boodschap van deze functionaliteit geeft een eenvoudig voorbeeld hoe je al je C broncode door het indent programma kunt laten bewerken alvorens te committen. Je kunt het instellen door het filter attribuut in je .gitattributes bestand te zetten zodat *.c bestanden door de "indent" filter gehaald worden:
*.c filter=indent
Vervolgens vertel je Git wat het "indent" filter doet bij smudge en clean:
$ git config --global filter.indent.clean indent
$ git config --global filter.indent.smudge cat
In dit geval zal Git, als je bestanden commit die met *.c overeenkomen, ze door het indent programma halen alvorens ze te committen, en ze door het cat programma halen alvorens ze op de schijf uit te checken. Het cat programma is eigenlijk een no-op: het geeft de gegevens onveranderd door. Deze combinatie zal effectief alle C broncode bestanden door indent filteren alvorens te committen.
Een ander interessant voorbeeld is $Date$ sleutelwoord expansie, in RCS stijl. Om dit goed te doen, moet je een klein script hebben dat een bestandsnaam pakt, de laatste commit datum voor dit project opzoekt, en de datum in dat bestand toevoegt. Hier volgt een klein Ruby script dat dat doet:
#! /usr/bin/env ruby
data = STDIN.read
last_date = `git log --pretty=format:"%ad" -1`
puts data.gsub('$Date$', '$Date: ' + last_date.to_s + '$')
Het enige dat het script doet is de laatste commit datum uit het git log commando halen, het in iedere $Date$ tekst stoppen die het in stdin ziet, en de resultaten afdrukken – het moet eenvoudig na te bouwen zijn in de taal waar je het beste in thuisbent. Je kunt dit bestand expand_date noemen en het in je pad stoppen. Nu moet je een filter in Git instellen (noem het dater), en het vertellen jouw expand_date filter te gebruiken om de bestanden tijdens checkout te 'besmeren'. Je zult een Perl expressie gebruiken om dat op te ruimen tijdens een commit:
$ git config filter.dater.smudge expand_date
$ git config filter.dater.clean 'perl -pe "s/\\\$Date[^\\\$]*\\\$/\\\$Date\\\$/"'
Dit stukje Perl haalt alles weg dat het in een $Date$ tekst ziet, om weer op het uitgangspunt uit te komen. Nu je filter klaar is, kun je het testen door een bestand aan te maken met het $Date$ sleutelwoord en dan een Git attribuut voor dat bestand in te stellen, die het nieuwe filter aanroept.
$ echo '# $Date$' > date_test.txt
$ echo 'date*.txt filter=dater' >> .gitattributes
Als je die veranderingen commit en het bestand opnieuw uitcheckt, zal je zien dat het sleutelwoord correct vervangen wordt:
$ git add date_test.txt .gitattributes
$ git commit -m "Testing date expansion in Git"
$ rm date_test.txt
$ git checkout date_test.txt
$ cat date_test.txt
# $Date: Tue Apr 21 07:26:52 2009 -0700$
Je ziet hier hoe krachtig deze techniek is voor gebruik in eigengemaakte toepassingen. Je moet wel voorzichtig zijn, om dat het .gitattributes bestand ook gecommit wordt en meegestuurd wordt met het project, maar het filter (in dit geval dater) niet; dus het zal niet overal werken. Als je deze filters ontwerpt, zouden ze in staat moeten zijn om netjes te falen en het project nog steeds goed te laten werken.
Je repository exporteren
De Git attribute gegevens staan je ook toe om interessante dingen te doen als je een archief van je project exporteert.
export-ignore
Je kunt Git vertellen dat sommige bestanden of directories niet geëxporteerd moeten worden bij het genereren van een archief. Als er een subdirectory of bestand is waarvan je niet wilt dat het wordt meegenomen in je archief bestand, maar dat je wel in je project ingecheckt wil hebben, dan kun je die bestanden bepalen met behulp van het export-ignore attribuut.
Bijvoorbeeld, stel dat je wat testbestanden in een test/ subdirectory hebt, en dat het geen zin heeft om die in de tarball export van je project mee te nemen. Dan kan je de volgende regel in je Git attributes bestand toevoegen:
test/ export-ignore
Als je nu git archive uitvoert om een tarball van je project te maken, zal die map niet meegenomen worden in het archief.
export-subst
Iets anders dat je kunt doen met je archieven is eenvoudige sleutelwoord vervanging. Git staat je toe om de tekst $Format:$ met een van de --pretty=format formaat afkortingen in één of meer bestanden te zetten. Veel voorbeelden van die formaatafkortingen zag je al in Hoofdstuk 2. Bijvoorbeeld, als je een bestand genaamd LAST_COMMIT wilt meenemen in je project, waarin de laatste commit datum automatisch wordt geïnjecteerd als git archive loopt, kun je het bestand als volgt instellen:
$ echo 'Last commit date: $Format:%cd$' > LAST_COMMIT
$ echo "LAST_COMMIT export-subst" >> .gitattributes
$ git add LAST_COMMIT .gitattributes
$ git commit -am 'adding LAST_COMMIT file for archives'
Als je git archive uitvoert, zal de inhoud van dat bestand, als mensen het archief bestand openen, er zo uit zien:
$ cat LAST_COMMIT
Last commit date: $Format:Tue Apr 21 08:38:48 2009 -0700$
Merge strategieën
Je kunt Git attributen ook gebruiken om Git te vertellen dat het verschillende merge strategieën moet gebruiken voor specifieke bestanden in je project. Een erg handige toepassing is Git te vertellen dat het bepaalde bestanden niet moet proberen te mergen als ze conflicten hebben, maar jouw versie moeten gebruiken in plaats van die van de ander.
Dit is handig als een branch in jouw project uiteen is gelopen of gespecialiseerd is, maar je wel in staat wilt zijn om veranderingen daarvan te mergen, en je wilt bepaalde bestanden negeren. Stel dat je een database instellingen bestand hebt dat database.xml heet en dat in twee branches verschillend is, en je wilt de andere branch mergen zonder jouw database bestand overhoop te halen. Je kunt dan een attribuut als volgt instellen:
database.xml merge=ours
Als je in de andere branch merged, dan zul je in plaats van merge conflicten met je database.xml bestand zoiets als dit zien:
$ git merge topic
Auto-merging database.xml
Merge made by recursive.
In dit geval blijft database.xml staan op de versie die je origineel al had.