Attributi di Git
Alcune di queste impostazioni possono anche essere specificate per un percorso, per fare in modo che Git applichi queste impostazioni solo per una sottodirectory o un sottoinsieme di files. Queste opzioni path-specific sono chiamate attributi di Git e sono impostati nel file .gitattributes in una delle tue directories (normalmente nella radice del progetto) oppure nel file .git/info/attributes se non vuoi che venga fatto il commit del file degli attributi del tuo progetto.
Usando gli attributi, puoi fare cose come specificare strategie di merge separate per files individuali o directories nel tuo progetto, comunicare a Git come fare diff per files non di testo, oppure fare in modo che Git filtri il contenuto prima del check all'interno o all'esterno di Git. In questa sezione imparerai come impostare alcuni degli attributi sui tuoi percorsi, nel tuo progetto Git, e vedere alcuni esempi di come usare questa caratteristica nella pratica.
Files Binari
Un trucco figo per il quale si possono usare gli attributi Git è comunicare a Git quali files siano binari (nel caso non sia capace di capirlo) e dargli istruzioni speciali riguardo a come gestire tali files. Per esempio, alcuni files di testo possono essere generati dalla macchina e non sottomissibili a diff, mentre altri files binari possono essere sottoposti a diff — vedremo come dire a Git cosa è cosa.
Identificare Files Binari
Alcuni files assomigliano a files di testo ma per il loro scopo vengono trattati come dati. Per esempio, i progetti Xcode di un Mac contengono un file che termina con .pbxproj, che è praticamente un dataset JSON (testo in chiaro nel formato javascript) scritto sul disco dall'IDE che registra i parametri di build e così via. Comunque tecnicamente è un file di testo, essendo tutto codice ASCII, non si vuole però trattarlo come tale perché è in realtà un leggero database — non è possibile eseguire un merge dei contenuti se due persone l'hanno modificato ed i diffs solitamente non sono d'aiuto. Il file è stato creato con lo scopo di essere usato dalla macchina. Infine lo si vuole trattare come un file binario.
Per comunicare a Git di trattare tutti i files pbxproj come files binari, bisogna aggiungere la riga seguente al file .gitattributes:
*.pbxproj -crlf -diff
Ora Git non proverà più a convertire o sistemare i problemi CRLF; non proverà nemmeno a calcolare o stampare diff per i cambiamenti in questo file quando esegui git show o git diff sul progetto. Nella serie 1.6 di Git è fornita una macro che equivale ad utilizzare -crlf -diff:
*.pbxproj binary
Diff di Files Binari
Nella serie 1.6 di Git, è possibile utilizzare funzionalità degli attributi Git per eseguire effettivamente diff di files binari. Questo può essere fatto comunicando a Git come convertire il file binario in formato testuale che possa essere comparato con un normale diff.
Files MS Word
Visto che questo è un metodo abbastanza figo e non molto conosciuto, lo analizzeremo con qualche esempio. Prima di tutto useremo questa tecnica per risolvere uno dei più fastidiosi problemi conosciuti dall'umanità: version-control per documenti Word. Ognuno sa che Word è il peggiore editor esistente; tuttavia, purtroppo, lo usano tutti. Se vogliamo eseguire il version-control per documenti Word, possiamo inserirli in un repository Git ed eseguire un commit ogni tanto; ma è un metodo così buono? Se eseguiamo git diff normalmente, vedremo solamente qualcosa del genere:
$ git diff
diff --git a/chapter1.doc b/chapter1.doc
index 88839c4..4afcb7c 100644
Binary files a/chapter1.doc and b/chapter1.doc differ
Non possiamo confrontare direttamente due versioni a meno che non si estraggano e le si controlli a mano, giusto? Ne deriva che possiamo farlo meglio utilizzando gli attributi Git. Inseriamo la linea seguente nel file .gitattributes:
*.doc diff=word
Questo comunica a Git che ogni file che corrisponde a questo pattern (.doc) deve utilizzare il filtro "word" nel caso si cerchi di visualizzarne un diff contenente modifiche. Cos'è il filtro "word"? Bisogna impostarlo. Ora configureremo Git per utilizzare il programma strings per convertire documenti Word in file di testo leggibili di cui possa fare un diff appropriato:
$ git config diff.word.textconv strings
Questo comando aggiunge una sezione al file .git/config che assomiglia a questa:
[diff "word"]
textconv = strings
Nota bene: esistono diversi tipi di files .doc. Alcuni utilizzano codifica UTF-16 o altre "codepages" e strings non sarà in grado di trovare nulla di utile.
Ora Git è al corrente che se prova ad eseguire diff tra i due snapshot, e qualunque dei files termina in .doc, deve eseguire questi files tramite il filtro "word", che è definito come il programma strings. Questo li rende effettivamente delle simpatiche versioni di testo dei files Word prima di tentare di eseguire il diff.
Vediamo ora un esempio. Ho inserito il Capitolo 1 di questo libro all'interno di Git, aggiunto un po' di testo nel paragrafo, e salvato il documento. In seguito ho eseguito git diff per vederne i cambiamenti:
$ git diff
diff --git a/chapter1.doc b/chapter1.doc
index c1c8a0a..b93c9e4 100644
--- a/chapter1.doc
+++ b/chapter1.doc
@@ -8,7 +8,8 @@ re going to cover Version Control Systems (VCS) and Git basics
re going to cover how to get it and set it up for the first time if you don
t already have it on your system.
In Chapter Two we will go over basic Git usage - how to use Git for the 80%
-s going on, modify stuff and contribute changes. If the book spontaneously
+s going on, modify stuff and contribute changes. If the book spontaneously
+Let's see if this works.
Git comunica in modo corretto e succinto che è stata aggiunta la stringa "Let’s see if this works", che è corretto. Non è perfetto — aggiunge un mucchio di altre cose alla fine — tuttavia certamente funziona. Se si vuole trovare o scrivere un convertitore Word-to-plain-text che lavori sufficientemente bene, la soluzione sarà incredibilmente efficace. Comunque, strings è disponibile per la maggior parte di sistemi Mac e Linux, quindi eseguirlo potrebbe essere una prima prova per molti files binari.
OpenDocument Text files
Lo stesso approccio usato per i file MS Word (*.doc) può essere utilizzato per i files di testo Opendocument (*.odt) creati da OpenOffice.org.
Agiungiamo la seguente riga al file .gitattributes:
*.odt diff=odt
Ora impostiamo il filtro diff odt in .git/config:
[diff "odt"]
binary = true
textconv = /usr/local/bin/odt-to-txt
I files di tipo OpenDocument sono in effetti cartelle compresse contenenti files (contenuto in formato XML, fogli di stile, immagini...). Bisogna quindi scrivere uno script che estragga il contenuto e lo restituisca come semplice testo. Creiamo un file /usr/local/bin/odt-to-txt (o anche in una directory differente) con il seguente contenuto:
#! /usr/bin/env perl
# Simplistic OpenDocument Text (.odt) to plain text converter.
# Author: Philipp Kempgen
if (! defined($ARGV[0])) {
print STDERR "No filename given!\n";
print STDERR "Usage: $0 filename\n";
exit 1;
}
my $content = '';
open my $fh, '-|', 'unzip', '-qq', '-p', $ARGV[0], 'content.xml' or die $!;
{
local $/ = undef; # slurp mode
$content = <$fh>;
}
close $fh;
$_ = $content;
s/<text:span\b[^>]*>//g; # remove spans
s/<text:h\b[^>]*>/\n\n***** /g; # headers
s/<text:list-item\b[^>]*>\s*<text:p\b[^>]*>/\n -- /g; # list items
s/<text:list\b[^>]*>/\n\n/g; # lists
s/<text:p\b[^>]*>/\n /g; # paragraphs
s/<[^>]+>//g; # remove all XML tags
s/\n{2,}/\n\n/g; # remove multiple blank lines
s/\A\n+//; # remove leading blank lines
print "\n", $_, "\n\n";
Rendiamolo eseguibile:
chmod +x /usr/local/bin/odt-to-txt
Ora git diff sarà in grado di comunicare cosa è cambiato nei files .odt.
Immagini
Un altro problema interessante che puoi risolvere in questo modo è eseguire diff di immagini. Un modo per farlo è di elaborare i files PNG tramite un filtro che ne estragga le informazioni EXIF — metadati codificati nella maggior parte dei formati delle immagini. Se scarichiamo ed installiamo il programma exiftool, possiamo utilizzarlo per convertire le immagini in testo riguardante i metadati, quindi il diff mostrerà almeno una rappresentazione testuale di cosa è successo:
$ echo '*.png diff=exif' >> .gitattributes
$ git config diff.exif.textconv exiftool
Se si rimpiazza un'immagine nel progetto e si esegue git diff, si ottiene qualcosa del genere:
diff --git a/image.png b/image.png
index 88839c4..4afcb7c 100644
--- a/image.png
+++ b/image.png
@@ -1,12 +1,12 @@
ExifTool Version Number : 7.74
-File Size : 70 kB
-File Modification Date/Time : 2009:04:17 10:12:35-07:00
+File Size : 94 kB
+File Modification Date/Time : 2009:04:21 07:02:43-07:00
File Type : PNG
MIME Type : image/png
-Image Width : 1058
-Image Height : 889
+Image Width : 1056
+Image Height : 827
Bit Depth : 8
Color Type : RGB with Alpha
Si può semplicemente vedere che la dimensione ed il peso dell'immagine sono entrambe cambiati.
Keyword Expansion
Gli sviluppatori abituati a sistemi come CVS o SVN richiedono spesso una keyword expansion tipica di quei sistemi. Il problema maggiore con questo su Git è che non è possibile modificare un file con informazioni per il commit dopo aver eseguito il commit, perché Git esegue prima un check del file. Comunque, è possibile inserire testo all'interno del file quando viene estratto e rimuoverlo prima che venga aggiunto al commit. Gli attributi Git forniscono due modi per farlo.
Innanzitutto, è possibile inserire il checksum SHA-1 di una bolla in un campo $Id$ del file in modo automatico. Se si imposta questo attributo in un file o insieme di files, allora la prossima volta verrà eseguito un check out di quel ramo, Git rimpiazzerà quel campo con lo SHA-1 della bolla. È importante notare che non è lo SHA del commit, ma della bolla stessa:
$ echo '*.txt ident' >> .gitattributes
$ echo '$Id$' > test.txt
La prossima volta che eseguiremo un check out di questo file, Git inserirà lo SHA della bolla:
$ rm test.txt
$ git checkout -- test.txt
$ cat test.txt
$Id: 42812b7653c7b88933f8a9d6cad0ca16714b9bb3 $
Comunque, questo risultato è di utilizzo limitato. Se hai usato la keyword substitution di CVS o Subversion, puoi includere un datastamp — lo SHA non è così utile, perché è un numero praticamente casuale e non puoi sapere se uno SHA sia o meno precedente di un altro.
Ne consegue che puoi scrivere i tuoi filtri per eseguire sostituzioni nei commit/checkout dei files. Questi sono i filtri "clean" e "smudge". Nel file .gitattributes, puoi impostare un filtro per un percorso particolare e quindi impostare gli scripts che processano files appena prima che ne venga eseguito un checkout ("smudge", vedi Figura 7-2) ed appena prima che ne venga eseguito un commit ("clean", vedi figura 7-3). Questi filtri possono essere impostati per fare tutte queste cose divertenti.
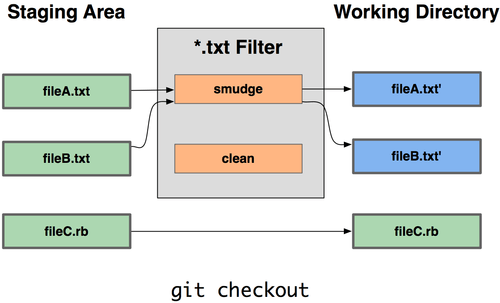
Figura 7-2. Filtro “smudge” eseguito al checkout.
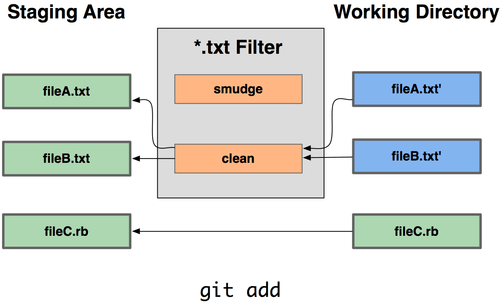
Figura 7-3. Filtro “clean” eseguito quando viene fatto lo stage dei files.
Il messaggio originale di commit per questa funzionalità fornisce un semplice esempio dell'eseguire tutto il nostro codice C durante il programma indent prima del commit. Puoi impostarlo assegnando all'attributo filter in .gitattributes il compito di filtrare files *.c con il filtro "indent":
*.c filter=indent
Diciamo poi a Git cosa farà il filtro "indent" in smudge e clean:
$ git config --global filter.indent.clean indent
$ git config --global filter.indent.smudge cat
In questo caso, quando verranno fatti commit di files che corrispondono a *.c, Git li eseguirà attraverso il programma indent prima di farne commits e quindi passarli al programma cat prima di rifarne un check nel disco. Il programma cat è praticamente una non-operazione: restituisce gli stessi dati che riceve in ingresso. Questa combinazione effettivamente filtra tutto il codice C tramite indent prima del commit.
Un altro esempio interessante è la keyword expansion $Date$, in stile RCS. Per farlo in modo appropriato, bisogna avere un piccolo script che dato in ingresso il nome di un file ne capisca la data dell'ultimo commit, ed inserisca la data nel file. Ad esempio questo è un piccolo script Ruby che esegue il compito:
#! /usr/bin/env ruby
data = STDIN.read
last_date = `git log --pretty=format:"%ad" -1`
puts data.gsub('$Date$', '$Date: ' + last_date.to_s + '$')
Lo script preleva la data dell'ultimo commit tramite il comando git log, lo allega ad ogni stringa $Date$ che trova in stdin, stampa il risultato — dovrebbe essere semplice da fare in ogni linguaggio con cui siete pratici. Questo file può essere chiamato expand_date ed essere posizionato nel path. Ora bisogna impostare un filtro in Git (chiamato dater) e comunicare di utilizzare il filtro expand_date per eseguire uno smudge dei files in checkout. Utilizzeremo un'espressione Perl per pulirlo al commit:
$ git config filter.dater.smudge expand_date
$ git config filter.dater.clean 'perl -pe "s/\\\$Date[^\\\$]*\\\$/\\\$Date\\\$/"'
Questo frammento di Perl toglie qualsiasi cosa veda nella stringa $Date$, per tornare al punto di partenza. Ora che il filtro è pronto, è possibile provarlo costruendo un file con la keyword $Date$ e quindi impostare un attributo Git per il file che richiami il nuovo filtro:
$ echo '# $Date$' > date_test.txt
$ echo 'date*.txt filter=dater' >> .gitattributes
Se esegui un commit per questi cambiamenti e quindi fai un checkout del file, noterai che la keyword è stata sostituita:
$ git add date_test.txt .gitattributes
$ git commit -m "Testing date expansion in Git"
$ rm date_test.txt
$ git checkout date_test.txt
$ cat date_test.txt
# $Date: Tue Apr 21 07:26:52 2009 -0700$
Si può vedere quanto sia potente questa tecnica per applicazioni personalizzate. Bisogna però prestare attenzione, infatti del file .gitattributes viene eseguito un commit e viene distribuito insieme al progetto, tuttavia non si può dire la stessa cosa per quanto riguarda il driver (in questo caso, dater); quindi non funzionerà ovunque. Quando costruisci questi filtri, dovrebbero essere in grado di non fallire in modo drastico e permettere al progetto di continuare a funzionare in modo appropriato.
Esportare il Repository
Gli attributi Git permettono inoltre di attuare operazioni interessanti quando si esporta un archivio del proprio progetto.
export-ignore
È possibile comunicare a Git di non esportare alcuni files o directories quando si genera un archivio. Nel caso ci sia una sottodirectory o file che non si vuole includere nell'archivio ma che si vuole comunque tenere nel progetto, è possibile determinare questi files tramite l'attributo export-ignore.
Per esempio, diciamo di avere dei files per i test in una sottodirectory test/, non avrebbe senso includerla in un tarball del progetto. È possibile aggiungere la seguente riga al file Git attributes:
test/ export-ignore
Ora, quando verrà eseguito git archive per creare la tarball del progetto, la directory non sarà inclusa nell'archivio.
export-subst
Un'altra cosa che è possibile fare per gli archivi è qualche semplice keyword substitution. Git permette di inserire la stringa $Format:$ in ogni file con uno qualsiasi degli shortcodes di formattazione --pretty=format, dei quali ne abbiamo visti alcuni nel Capitolo 2. Per esempio, nel caso si voglia includere un file chiamato LAST_COMMIT nel progetto, e l'ultima data di commit è stata inserita automaticamente al suo interno all'esecuzione di git archive, è possibile impostare il file in questo modo:
$ echo 'Last commit date: $Format:%cd$' > LAST_COMMIT
$ echo "LAST_COMMIT export-subst" >> .gitattributes
$ git add LAST_COMMIT .gitattributes
$ git commit -am 'adding LAST_COMMIT file for archives'
All'esecuzione di git archive, il contenuto del file quando qualcuno aprirà l'archivio sarà di questo tipo:
$ cat LAST_COMMIT
Last commit date: $Format:Tue Apr 21 08:38:48 2009 -0700$
Merge Strategies
È possibile inoltre utilizzare attributi Git per comunicare a Git di utilizzare differenti strategie di merge per files specifici nel progetto. Un opzione molto utile è comunicare a Git di non provare ad eseguire merge di files specifici quando sussistono conflitti, ma, invece, di la propria parte di merge sopra quella di qualcun altro.
Questo è utile se un ramo nel progetto presenta divergenze o è specializzato, ma si vuole essere in grado di fare merge dei cambiamenti su di esso, e si vogliono ignorare alcuni files. Diciamo di avere un database di opzioni chiamato database.xml che è differente in due rami, e si vuole eseguire un marge nell'altro ramo senza fare confusione all'interno del database. È possibile impostare un attributo in questo modo:
database.xml merge=ours
Nel caso si voglia fare un merge nell'altro ramo, invece di avere conflitti di merge con il file database.xml, si noterà qualcosa di simile a:
$ git merge topic
Auto-merging database.xml
Merge made by recursive.
In questo caso, database.xml rimarrà a qualsiasi versione si aveva in origine.