Gli oggetti di Git
Git è un filesystem indirizzabile per contenuto. Magnifico, ma che cosa significa? Significa che il nucleo di Git è un semplice database chiave-valore. Puoi inserire qualsiasi tipo di contenuto
al suo interno, e ti verrà restituita una chiave che potrai usare per recuperare quel contenuto in qualsiasi momento, quando vorrai. Come dimostrazione puoi usare il comando plumbing hash-object che accetta dei dati, li salva nella vostra directory .git e restituisce la chiave associata ai dati salvati. Per prima cosa create un nuovo repository Git e verificate che la directory objects non contenga nulla:
$ mkdir test
$ cd test
$ git init
Initialized empty Git repository in /tmp/test/.git/
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
$
Git ha creato la directory objects e, al suo interno, le subdirectory pack e info, ma non ci sono file. Ora inseriamo del testo nel tuo database di Git:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
L’opzione -w dice a hash-object di salvare l'oggetto: se la omettessimo il comando restituirebbe semplicemente quale chiave verrebbe associata all’oggetto. --stdin dice al comando di leggere il contenuto dallo standard input: se non lo specifichi hash-object si aspetta il percorso di un file. L'output del comando è un checksum di 40 caratteri. Questo è un hash SHA-1, un checksum del contenuto che viene salvato con la sua intestazione, ma questo lo vedremo fra poco. Ora vediamo come Git ha salvato i tuoi dati:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Ora troverai un file nella directory objects. Questo è il modo in cui Git salva inizialmente il contenuto: un singolo file per ogni porzione di contenuto, con il nome del checksum SHA-1 del contenuto e del suo header. I primi 2 caratteri dello SHA sono il nome della subdirectory, mentre gli altri 38 sono il nome del file.
Puoi estrarre il contenuto memorizzato in Git con il comando cat-file. Questo comando è una specie di coltellino svizzero per ispezionare gli oggetti Git. Usandolo con l’opzione -p è possibile dire al comando cat-file d’interpretare il tipo di contenuto e mostrartelo in un modo più elegante:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
Ora puoi aggiungere dell’altro contenuto a Git ed estrarlo nuovamente. Lo puoi possibile far anche con il contenuto dei file. Puoi, per esempio, implementare un semplice controllo di versione di un file. Come prima cosa crea un nuovo file e salva il suo contenuto nel database:
$ echo 'versione 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
Quindi scrivi un nuovo contenuto nel file e risalvalo:
$ echo 'versione 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
Il tuo database conterrà le due nuove versioni del file così come il primo contenuto che avevi già salvato:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Ora puoi riportare il file alla prima versione:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
versione 1
o alla seconda:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
versione 2
Ricordare la chiave SHA-1 di ogni versione del tuo file non è per niente pratico e, come hai visto, non viene salvato nemmeno il nome del file, ma solo il suo contenuto. Questo tipo di oggetto a chiamato blob. Puoi fare in modo che Git ti restituisca il tipo di ciascun oggetto conservato al suo interno, data la sua chiave SHA-1, con cat-file -t:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob
L’albero degli oggetti
Il prossimo argomento che guarderemo è l'albero degli oggetti, che risolve il problema del salvataggio del nome del file e ci permette di salvare un gruppo di file contemporaneamente. Git salva il contenuto in modo simile ad un filesystem UNIX, ma un po’ più semplificato. Tutto il suo contenuto è salvato come albero o blob, dove gli alberi corrispondono alle directory UNIX e i blob corrispondono più o meno agli inode o ai contenuti dei file. Un singolo albero contiene una o più voci, ognuna delle quali contiene un puntatore SHA-1 a un blob o a un altro con i suoi modi, tipi e nomi. Ad esempio, l'albero più recente nel progetto simplegit potrebbe assomigliare a questo:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
La sintassi master^{tree} indica che l’ultima commit sul tuo branch ‘master’ punta a questo albero.
Nota che la directory lib non è un blob ma un puntatore a un altro albero:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
Concettualmente, i dati che vengono salvati da Git sono simili a quelli in Figura 9-1.
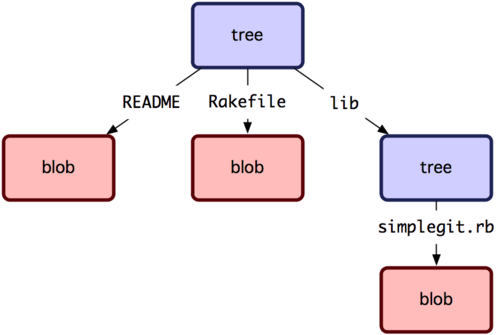
Figura 9-1. Versione semplificata del modello dei dati di Git.
Puoi creare il tuo albero come vuoi. Git normalmente crea un albero partendo dallo stato della tua area di staging o dall’indice e scrive albero partendo da lì. Quindi, per creare un albero devi prima creare un indice mettendo in staging alcuni file. Per creare un indice con una singola voce - la prima versione del tuo test.txt - puoi usare il comando plumbing update-index. Usando questo
comando aggiungi artificialmente la versione precedente del file test.txt a una nuova area di staging.
Devi usare l'opzione --add perché il file non esiste ancora nella tua area di staging (e in effetti ancora non hai nemmeno un'area di staging) e l'opzione --cacheinfo perché il file che stai aggiungendo non è nella tua directory ma nel tuo database. Per finire, specifica il modo l’hash SHA-1 e il nome del file:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt
In questo caso, stai specificando il modo 100644 che significa che si tratta di un file normale.
Altre opzioni sono 100755 (che significa che il file è eseguibile) e 120000 (che specifica un link simbolico). Il modo è preso dai modi normali di UNIX, ma è molto meno flessibile: questi tre sono gli unici validi per i file (blob) in Git (anche se ci sono altri modi utilizzati per le directory ed i sottomoduli).
Ora puoi usare il comando write-tree per creare l'area di staging da un albero. L'opzione -w
non è necessaria, perché l'esecuzione di write-tree crea automaticamente un oggetto albero a partire dallo stato dell'indice se l’albero ancora non esiste:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
Puoi anche verificare che si tratta di un oggetto albero:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
Ora creerai un nuovo albero con la seconda versione di test.txt e un nuovo file:
$ echo ‘nuovo file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txt
La tua area di staging ora contiene la nuova versione di test.txt così come il nuovo file new.txt Scrivete l'albero (registrando lo stato dell'area di staging o indice in un oggetto albero) e osservate a cosa assomiglia
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Nota che questo albero ha entrambe le voci e anche che l’hash SHA di test.txt è lo stesso SHA della precedente "versione 2" (1f7a7a). Solo per divertimento, aggiungi il primo albero come subdirectory di questo attuale. Puoi vedere gli alberi nella tua area di staging eseguendo read-tree. Potrai vedere un albero esistente nella tua area di staging come sotto-albero con l'opzione --prefix di read-tree:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Se hai creato una directory di lavoro dal nuovo albero che hai appena scritto, otterrai i due file nel primo livello della directory e una sotto-directory chiamata bak, che contiene la prima versione del file test.txt. Puoi pensare ai dati contenuti da Git per questa strutture come quelli della Figura 9-2.
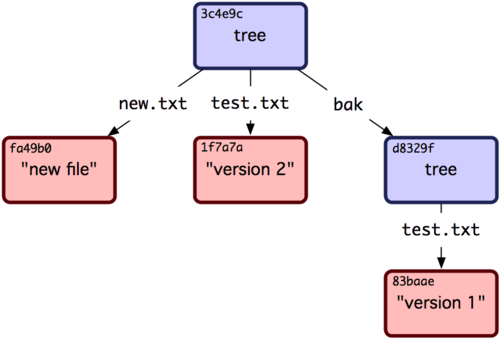
Figura 9-2. La struttura dei contenuti per i vostri dati di Git.
Oggetti Commit
A questo punto avrai tre alberi che specificano le diverse istantanee (snapshot) del tuo progetto delle quali vuoi tenere traccia, ma rimane il problema iniziale: devi ricordare tutti e tre gli hash SHA-1 per poter recuperare le istantanee. Inoltre non hai nessuna informazione su chi ha salvato le istantanee, né quando le hai salvate né tantomeno perché. Queste sono le informazioni che gli oggetti commit registrano per te.
Per creare un oggetto commit esegui commit-tree specificando un singolo albero SHA-1 e, se esiste, qual’è la commit immediatamente precedente. Comincia con il primo albero che hai scritto:
$ echo 'prima commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Ora puoi analizzare il tuo nuovo oggetto commit con cat-file:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <[email protected]> 1243040974 -0700
committer Scott Chacon <[email protected]> 1243040974 -0700
prima commit
Il formato di un oggetto commit è semplice: specifica l'albero di primo livello per l’istantanea del progetto in quel dato punto, mentre le informazioni sull’autore delle modifiche o della commit vengono estratte dalle tue impostazioni user.name e user.email con il timestamp corrente, una linea vuota ed infine il messaggio di commit.
Scriviamo gli altri due oggetti commit, ognuno dei quali fa riferimento alla commit che le hanno preceduti:
$ echo 'seconda commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo ‘terza commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9
Ognuno dei tre oggetti commit punta ad uno dei tre alberi delle istantanee che hai creato.
Ora hai una vera e propria cronologia di Git che puoi consultare con il comando git log, se lo esegui con l’hash SHA-1 dell'ultima commit vedrai:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:15:24 2009 -0700
terza commit
bak/test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:14:29 2009 -0700
seconda commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletions(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:09:34 2009 -0700
prima commit
test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
Fantastico. Hai appena eseguito tutte le operazioni di basso livello per costruire una cronologia di Git senza utilizzare nessuno dei comandi del front end. Questo è essenzialmente quello che Git fa quando esegui i comandi git add e git commit: salva i blob per i file che sono cambiati, aggiorna l'indice, scrive gli alberi e scrive gli oggetti commit che fanno riferimento agli alberi di primo livello e le commit immediatamente precedenti a questi. Questi tre oggetti Git principali (il blob, l'albero, e la commit) sono inizialmente salvati come file separati nella tua directory .git/objects. Di seguito puoi vedere tutti gli oggetti nella directory di esempio, commentati con quello che contengono:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
Se segui tutti i puntatori interni otterrai un grafico degli oggetti simile a quelli in Figura 9-3.
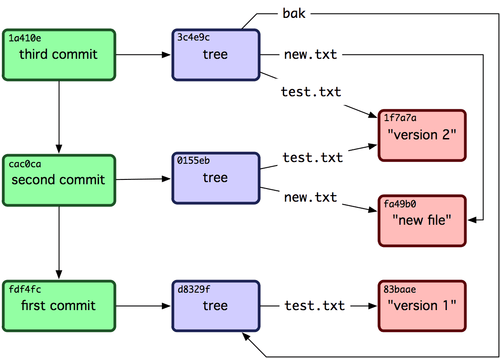
Figura 9-3. Tutti gli oggetti nella tua directory Git.
Il salvataggio degli oggetti
In precedenza ho menzionato il fatto che insieme al contenuto viene salvato anche una intestazione. Prendiamoci un minuto per capire come Git salva i propri oggetti. Vedremo come salvare un oggetto blob - in questo caso la stringa "what is up, doc?" - interattivamente con il linguaggio di scripting Ruby. Potete lanciare Ruby in modalità interattiva con il comando irb:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"
Git costruisce una intestazione che comincia con il tipo dell'oggetto, in questo caso un blob, aggiunge uno spazio seguito dalla dimensione del contenuto ed infine da un null byte:
>> header = "blob #{content.length}\0"
=> "blob 16\000"
Git concatena l’intestazione e il contenuto originale e calcola il checksum SHA-1 del risultato. Puoi calcolare lo SHA-1 di una stringa in Ruby includendo la libreria SHA1 digest con il comando require e invocando Digest::SHA1.hexdigest():
>> store = header + content
=> "blob 16\000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
Git comprime il nuovo contenuto con zlib, cosa che potete fare in Ruby con la libreria zlib.
Prima avrai bisogno di includere la libreria ed invocare Zlib::Deflate.deflate() sul contenuto:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"
Infine, scrivi il contenuto zlib-deflated in un oggetto sul disco. Determinerai il percorso dell'oggetto che vuoi scrivere (i primi due caratteri dello SHA-1 sono il nome della subdirectory e gli ultimi 38 caratteri sono il nome del file contenuto in quella directory). In Ruby puoi usare la funzione FileUtils.mkdir_p() per creare la subdirectory, se questa non esiste. Apri di seguito il file con File.open() e scrivi nel file il contenuto ottenuto in precedenza, chiamando
write() sul file handler risultante:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32
Questo è tutto - hai creato un oggetto Git valido di tipo blob. Tutti gli oggetti Git sono salvati nello stesso modo, solo con tipi differenti. Invece della stringa blob, l’intestazione comincerà con commit o tree. Inoltre, sebbene il contenuto del blob può essere praticamente qualsiasi cosa, i contenuti commit e tree sono formattati in modo molto dettagliato.