Gravando Alterações no Repositório
Você tem um repositório Git e um checkout ou cópia funcional dos arquivos para esse projeto. Você precisa fazer algumas mudanças e fazer o commit das partes destas mudanças em seu repositório cada vez que o projeto atinge um estado no qual você queira gravar.
Lembre-se que cada arquivo em seu diretório de trabalho pode estar em um de dois estados: monitorado ou não monitorado. Arquivos monitorados são arquivos que estavam no último snapshot; podendo estar inalterados, modificados ou selecionados. Arquivos não monitorados são todo o restante — qualquer arquivo em seu diretório de trabalho que não estava no último snapshot e também não estão em sua área de seleção. Quando um repositório é inicialmente clonado, todos os seus arquivos estarão monitorados e inalterados porque você simplesmente os obteve e ainda não os editou.
Conforme você edita esses arquivos, o Git passa a vê-los como modificados, porque você os alterou desde seu último commit. Você seleciona esses arquivos modificados e então faz o commit de todas as alterações selecionadas e o ciclo se repete. Este ciclo é apresentado na Figura 2-1.
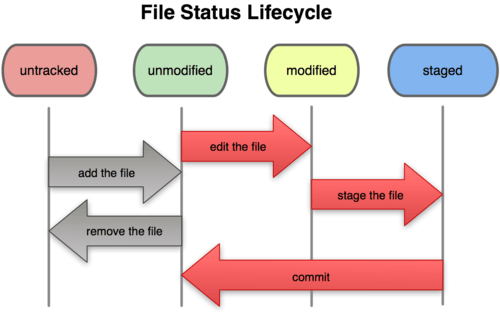
Figura 2-1. O ciclo de vida dos status de seus arquivos.
Verificando o Status de Seus Arquivos
A principal ferramenta utilizada para determinar quais arquivos estão em quais estados é o comando git status. Se você executar este comando diretamente após uma clonagem, você deverá ver algo similar a isso:
$ git status
# On branch master
nothing to commit (working directory clean)
Isso significa que você tem um diretório de trabalho limpo — em outras palavras, não existem arquivos monitorados e modificados. Git também não encontrou qualquer arquivo não monitorado, caso contrário eles seriam listados aqui. Por fim, o comando lhe mostra em qual branch você se encontra. Por enquanto, esse sempre é o master, que é o padrão; você não deve se preocupar com isso. No próximo capítulo nós vamos falar sobre branches e referências em detalhes.
Vamos dizer que você adicione um novo arquivo em seu projeto, um simples arquivo README. Caso o arquivo não exista e você execute git status, você verá o arquivo não monitorado dessa forma:
$ vim README
$ git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# README
nothing added to commit but untracked files present (use "git add" to track)
Você pode ver que o seu novo arquivo README não está sendo monitorado, pois está listado sob o cabeçalho "Untracked files" na saída do comando status. Não monitorado significa basicamente que o Git está vendo um arquivo que não existia na última captura (commit); o Git não vai incluí-lo nas suas capturas de commit até que você o diga explicitamente que assim o faça. Ele faz isso para que você não inclua acidentalmente arquivos binários gerados, ou outros arquivos que você não têm a intenção de incluir. Digamos, que você queira incluir o arquivo README, portanto vamos começar a monitorar este arquivo.
Monitorando Novos Arquivos
Para passar a monitorar um novo arquivo, use o comando git add. Para monitorar o arquivo README, você pode rodar isso:
$ git add README
Se você rodar o comando status novamente, você pode ver que o seu arquivo README agora está sendo monitorado e está selecionado:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
#
Você pode dizer que ele está selecionado pois está sob o cabeçalho “Changes to be committed”. Se você commitar neste ponto, a versão do arquivo no momento em que você rodou o comando git add é a que estará na captura (snapshot) do histórico. Você deve se lembrar que quando rodou o comando git init anteriormente, logo em seguida rodou o comando git add (arquivos) — fez isso para passar a monitorar os arquivos em seu diretório. O comando git add recebe um caminho de um arquivo ou diretório; se é de um diretório, o comando adiciona todos os arquivos do diretório recursivamente.
Selecionando Arquivos Modificados
Vamos alterar um arquivo que já está sendo monitorado. Se você alterar um aquivo previamente monitorado chamado benchmarks.rb e então rodar o comando status novamente, você terá algo semelhante a:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: benchmarks.rb
#
O arquivo benchmarks.rb aparece sob a seção chamada “Changes not staged for commit” — que significa que um arquivo monitorado foi modificado no diretório de trabalho, mas ainda não foi selecionado (staged). Para selecioná-lo, utilize o comando git add (é um comando com várias funções — você o utiliza para monitorar novos arquivos, selecionar arquivos, e para fazer outras coisas como marcar como resolvido aquivos com conflito). Agora vamos rodar o comando git add para selecionar o arquivo benchmarks.rb, e então rodar git status novamente:
$ git add benchmarks.rb
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
# modified: benchmarks.rb
#
Ambos os arquivos estão selecionados e serão consolidados no seu próximo commit. Neste momento, vamos supor que você lembrou de uma mudança que queria fazer no arquivo benchmarks.rb antes de commitá-lo. Você o abre novamente e faz a mudança, e então está pronto para commitar. No entanto, vamos rodar git status mais uma vez:
$ vim benchmarks.rb
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
# modified: benchmarks.rb
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: benchmarks.rb
#
Que diabos? Agora o arquivo benchmarks.rb aparece listado como selecionado e não selecionado. Como isso é possível? Acontece que o Git seleciona um arquivo exatamente como ele era quando o comando git add foi executado. Se você fizer o commit agora, a versão do benchmarks.rb como estava na última vez que você rodou o comando git add é que será incluída no commit, não a versão do arquivo que estará no seu diretório de trabalho quando rodar o comando git commit. Se você modificar um arquivo depois que rodou o comando git add, terá de rodar o git add de novo para selecionar a última versão do arquivo:
$ git add benchmarks.rb
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
# modified: benchmarks.rb
#
Ignorando Arquivos
Muitas vezes, você terá uma classe de arquivos que não quer que o Git automaticamente adicione ou mostre como arquivos não monitorados. Normalmente estes arquivos são gerados automaticamente como arquivos de log ou produzidos pelo seu sistema de build. Nestes casos, você pode criar um arquivo contendo uma lista de padrões a serem checados chamado .gitignore. Eis um exemplo de arquivo .gitignore:
$ cat .gitignore
*.[oa]
*~
A primeira linha fala para o Git ignorar qualquer arquivo finalizado em .o ou .a — arquivos objetos e archive (compactados) que devem ter produto da construção (build) de seu código. A segunda linha fala para o Git ignorar todos os arquivos que terminam com um til (~), os quais são utilizados por muitos editores de texto como o Emacs para marcar arquivos temporários. Você também pode incluir um diretório log, tmp ou pid; documentação gerada automaticamente; e assim por diante. Configurar um arquivo .gitignore antes de começar a trabalhar, normalmente é uma boa ideia, pois evita que você commite acidentalmente arquivos que não deveriam ir para o seu repositório Git.
As regras para os padrões que você pode pôr no arquivo .gitignore são as seguintes:
- Linhas em branco ou iniciando com
#são ignoradas. - Padrões glob comuns funcionam.
- Você pode terminar os padrões com uma barra (
/) para especificar diretórios. - Você pode negar um padrão ao iniciá-lo com um ponto de exclamação (
!).
Padrões glob são como expressões regulares simples que os shells usam. Um asterísco (*) significa zero ou mais caracteres; [abc] condiz com qualquer um dos caracteres de dentro dos colchetes (nesse caso, a, b, ou c); um ponto de interrogação (?) condiz com um único caractere; e os caracteres separados por hífen dentro de colchetes ([0-9]) condizem à qualquer um dos caracteres entre eles (neste caso, de 0 à 9).
Segue um outro exemplo de arquivo .gitignore:
# um comentário - isto é ignorado
# sem arquivos terminados em .a
*.a
# mas rastreie lib.a, mesmo que você tenha ignorado arquivos terminados em .a acima
!lib.a
# apenas ignore o arquivo TODO na raiz, não o subdiretório TODO
/TODO
# ignore todos os arquivos no diretório build/
build/
# ignore doc/notes.txt mas, não ignore doc/server/arch.txt
doc/*.txt
Visualizando Suas Mudanças Selecionadas e Não Selecionadas
Se o comando git status for muito vago — você quer saber exatamente o que você alterou, não apenas quais arquivos foram alterados — você pode utilizar o comando git diff. Nós trataremos o comando git diff em mais detalhes posteriormente; mas provavelmente você vai utilizá-lo com frequência para responder estas duas perguntas: O que você alterou, mas ainda não selecionou (stage)? E o que você selecionou, que está para ser commitado? Apesar do comando git status responder essas duas perguntas de maneira geral, o git diff mostra as linhas exatas que foram adicionadas e removidas — o patch, por assim dizer.
Vamos dizer que você edite e selecione o arquivo README de novo e então edite o arquivo benchmarks.rb sem selecioná-lo. Se você rodar o comando status, você novamente verá algo assim:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: benchmarks.rb
#
Para ver o que você alterou mas ainda não selecionou, digite o comando git diff sem nenhum argumento:
$ git diff
diff --git a/benchmarks.rb b/benchmarks.rb
index 3cb747f..da65585 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -36,6 +36,10 @@ def main
@commit.parents[0].parents[0].parents[0]
end
+ run_code(x, 'commits 1') do
+ git.commits.size
+ end
+
run_code(x, 'commits 2') do
log = git.commits('master', 15)
log.size
Este comando compara o que está no seu diretório de trabalho com o que está na sua área de seleção (staging). O resultado te mostra as mudanças que você fez que ainda não foram selecionadas.
Se você quer ver o que selecionou que irá no seu próximo commit, pode utilizar git diff --cached. (Nas versões do Git 1.6.1 e superiores, você também pode utilizar git diff --staged, que deve ser mais fácil de lembrar.) Este comando compara as mudanças selecionadas com o seu último commit:
$ git diff --cached
diff --git a/README b/README
new file mode 100644
index 0000000..03902a1
--- /dev/null
+++ b/README2
@@ -0,0 +1,5 @@
+grit
+ by Tom Preston-Werner, Chris Wanstrath
+ http://github.com/mojombo/grit
+
+Grit is a Ruby library for extracting information from a Git repository
É importante notar que o git diff por si só não mostra todas as mudanças desde o último commit — apenas as mudanças que ainda não foram selecionadas. Isso pode ser confuso, pois se você selecionou todas as suas mudanças, git diff não te dará nenhum resultado.
Como um outro exemplo, se você selecionar o arquivo benchmarks.rb e então editá-lo, você pode utilizar o git diff para ver as mudanças no arquivo que estão selecionadas, e as mudanças que não estão:
$ git add benchmarks.rb
$ echo '# test line' >> benchmarks.rb
$ git status
# On branch master
#
# Changes to be committed:
#
# modified: benchmarks.rb
#
# Changes not staged for commit:
#
# modified: benchmarks.rb
#
Agora você pode utilizar o git diff para ver o que ainda não foi selecionado:
$ git diff
diff --git a/benchmarks.rb b/benchmarks.rb
index e445e28..86b2f7c 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -127,3 +127,4 @@ end
main()
##pp Grit::GitRuby.cache_client.stats
+# test line
E executar git diff --cached para ver o que você já alterou para o estado staged até o momento:
$ git diff --cached
diff --git a/benchmarks.rb b/benchmarks.rb
index 3cb747f..e445e28 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -36,6 +36,10 @@ def main
@commit.parents[0].parents[0].parents[0]
end
+ run_code(x, 'commits 1') do
+ git.commits.size
+ end
+
run_code(x, 'commits 2') do
log = git.commits('master', 15)
log.size
Fazendo Commit de Suas Mudanças
Agora que a sua área de seleção está do jeito que você quer, você pode fazer o commit de suas mudanças. Lembre-se que tudo aquilo que ainda não foi selecionado — qualquer arquivo que você criou ou modificou que você não tenha rodado o comando git add desde que editou — não fará parte deste commit. Estes arquivos permanecerão como arquivos modificados em seu disco.
Neste caso, a última vez que você rodou git status, viu que tudo estava selecionado, portanto você está pronto para fazer o commit de suas mudanças. O jeito mais simples é digitar git commit:
$ git commit
Ao fazer isso, seu editor de escolha é acionado. (Isto é configurado através da variável de ambiente $EDITOR de seu shell - normalmente vim ou emacs, apesar de poder ser configurado o que você quiser utilizando o comando git config --global core.editor como visto no Capítulo 1).
O editor mostra o seguinte texto (este é um exemplo da tela do Vim):
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
# modified: benchmarks.rb
~
~
~
".git/COMMIT_EDITMSG" 10L, 283C
Você pode ver que a mensagem default do commit contém a última saída do comando git status comentada e uma linha vazia no início. Você pode remover estes comentários e digitar sua mensagem de commit, ou pode deixá-los ai para ajudar a lembrar o que está commitando. (Para um lembrete ainda mais explícito do que foi modificado, você pode passar a opção -v para o git commit. Ao fazer isso, aparecerá a diferença (diff) da sua mudança no editor para que possa ver exatamente o que foi feito.) Quando você sair do editor, o Git criará o seu commit com a mensagem (com os comentários e o diff retirados).
Alternativamente, você pode digitar sua mensagem de commit junto ao comanto commit ao especificá-la após a flag -m, assim:
$ git commit -m "Story 182: Fix benchmarks for speed"
[master]: created 463dc4f: "Fix benchmarks for speed"
2 files changed, 3 insertions(+), 0 deletions(-)
create mode 100644 README
Agora você acabou de criar o seu primeiro commit! Você pode ver que o commit te mostrou uma saída sobre ele mesmo: qual o branch que recebeu o commit (master), qual o checksum SHA-1 que o commit teve (463dc4f), quantos arquivos foram alterados, e estatísticas a respeito das linhas adicionadas e removidas no commit.
Lembre-se que o commit grava a captura da área de seleção. Qualquer coisa que não foi selecionada ainda permanece lá modificada; você pode fazer um outro commit para adicioná-la ao seu histórico. Toda vez que você faz um commit, está gravando a captura do seu projeto o qual poderá reverter ou comparar posteriormente.
Pulando a Área de Seleção
Embora possa ser extraordinariamente útil para a elaboração de commits exatamente como você deseja, a área de seleção às vezes é um pouco mais complexa do que você precisa no seu fluxo de trabalho. Se você quiser pular a área de seleção, o Git provê um atalho simples. Informar a opção -a ao comando git commit faz com que o Git selecione automaticamente cada arquivo que está sendo monitorado antes de realizar o commit, permitindo que você pule a parte do git add:
$ git status
# On branch master
#
# Changes not staged for commit:
#
# modified: benchmarks.rb
#
$ git commit -a -m 'added new benchmarks'
[master 83e38c7] added new benchmarks
1 files changed, 5 insertions(+), 0 deletions(-)
Note que, neste caso, você não precisa rodar o git add no arquivo benchmarks.rb antes de fazer o commit.
Removendo Arquivos
Para remover um arquivo do Git, você tem que removê-lo dos arquivos que estão sendo monitorados (mais precisamente, removê-lo da sua área de seleção) e então fazer o commit. O comando git rm faz isso e também remove o arquivo do seu diretório para você não ver ele como arquivo não monitorado (untracked file) na próxima vez.
Se você simplesmente remover o arquivo do seu diretório, ele aparecerá em “Changes not staged for commit” (isto é, fora da sua área de seleção ou unstaged) na saida do seu git status:
$ rm grit.gemspec
$ git status
# On branch master
#
# Changes not staged for commit:
# (use "git add/rm <file>..." to update what will be committed)
#
# deleted: grit.gemspec
#
Em seguida, se você rodar git rm, a remoção do arquivo é colocada na área de seleção:
$ git rm grit.gemspec
rm 'grit.gemspec'
$ git status
# On branch master
#
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# deleted: grit.gemspec
#
Na próxima vez que você fizer o commit, o arquivo sumirá e não será mais monitorado. Se você modificou o arquivo e já o adicionou na área de seleção, você deve forçar a remoção com a opção -f. Essa é uma funcionalidade de segurança para prevenir remoções acidentais de dados que ainda não foram gravados em um snapshot e não podem ser recuperados do Git.
Outra coisa útil que você pode querer fazer é manter o arquivo no seu diretório, mas apagá-lo da sua área de seleção. Em outras palavras, você quer manter o arquivo no seu disco rígido mas não quer que o Git o monitore mais. Isso é particularmente útil se você esqueceu de adicionar alguma coisa no seu arquivo .gitignore e acidentalmente o adicionou, como um grande arquivo de log ou muitos arquivos .a compilados. Para fazer isso, use a opção --cached:
$ git rm --cached readme.txt
Você pode passar arquivos, diretórios, e padrões de nomes de arquivos para o comando git rm. Isso significa que você pode fazer coisas como:
$ git rm log/\*.log
Note a barra invertida (\) na frente do *. Isso é necessário pois o Git faz sua própria expansão no nome do arquivo além da sua expansão no nome do arquivo no shell. Esse comando remove todos os arquivos que tem a extensão .log no diretório log/. Ou, você pode fazer algo como isso:
$ git rm \*~
Esse comando remove todos os arquivos que terminam com ~.
Movendo Arquivos
Diferente de muitos sistemas VCS, o Git não monitora explicitamente arquivos movidos. Se você renomeia um arquivo, nenhum metadado é armazenado no Git que identifique que você renomeou o arquivo. No entanto, o Git é inteligente e tenta descobrir isso depois do fato — lidaremos com detecção de arquivos movidos um pouco mais tarde.
É um pouco confuso que o Git tenha um comando mv. Se você quiser renomear um arquivo no Git, você pode fazer isso com
$ git mv arquivo_origem arquivo_destino
e funciona. De fato, se você fizer algo desse tipo e consultar o status, você verá que o Git considera que o arquivo foi renomeado:
$ git mv README.txt README
$ git status
# On branch master
# Your branch is ahead of 'origin/master' by 1 commit.
#
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# renamed: README.txt -> README
#
No entanto, isso é equivalente a rodar algo como:
$ mv README.txt README
$ git rm README.txt
$ git add README
O Git descobre que o arquivo foi renomeado implicitamente, então ele não se importa se você renomeou por este caminho ou com o comando mv. A única diferença real é que o comando mv é mais conveniente, executa três passos de uma vez. O mais importante, você pode usar qualquer ferramenta para renomear um arquivo, e usar add/rm depois, antes de consolidar com o commit.