Wgrywanie zmian do projektu
Znasz już różne sposoby pracy, oraz powinieneś posiadać solidne podstawy używania Gita. W tej sekcji, nauczysz się kilku najczęstszych sposobów aby uczestniczyć w projekcie.
Główną trudnością podczas opisywania tego procesu, jest bardzo duża różnorodność sposobów w jaki jest to realizowane. Ponieważ Git jest bardzo elastycznym narzędziem, ludzie mogą i współpracują ze sobą na różne sposoby, dlatego też trudne jest pokazanie w jaki sposób Ty powinieneś - każdy projekt jest inny. Niektóre ze zmiennych które warto wziąć pod uwagę to ilość aktywnych współpracowników, wybrany sposób przepływów pracy, uprawnienia, oraz prawdopodobnie sposób współpracy z zewnętrznymi programistami.
Pierwszą zmienną jest ilość aktywnych współpracowników. Ilu aktywnych współpracowników/programistów aktywnie wgrywa zmiany do projektu, oraz jak często? Najczęściej będzie to sytuacja, w której uczestniczy dwóch lub trzech programistów, wgrywających kilka razy na dzień zmiany (lub nawet mniej, przy projektach nie rozwijanych aktywnie). Dla bardzo dużych firm lub projektów, ilość programistów może wynieść nawet tysiące, z dziesiątkami lub nawet setkami zmian wgrywanych każdego dnia. Jest to bardzo ważne, ponieważ przy zwiększającej się liczbie programistów, wypływa coraz więcej problemów podczas włączania efektów ich prac. Zmiany które próbujesz wgrać, mogą stać się nieużyteczne, lub niepotrzebne ze względu na zmiany innych osób z zespołu. Tylko w jaki sposób zachować spójność kodu i poprawność wszystkich przygotowanych łatek?
Następną zmienną jest sposób przepływu pracy w projekcie. Czy jest scentralizowany, w którym każdy programista ma równy dostęp do wgrywania kodu? Czy projekt posiada głównego opiekuna, lub osobę integrującą, która sprawdza wszystkie łatki? Czy wszystkie łatki są wzajemnie zatwierdzane? Czy uczestniczysz w tym procesie? Czy funkcjonuje porucznik, do którego musisz najpierw przekazać swoje zmiany?
Następnym elementem są uprawnienia do repozytorium. Sposób pracy z repozytorium do którego możesz wgrywać zmiany bezpośrednio, jest zupełnie inny, od tego w którym masz dostęp tylko do odczytu. Jeżeli nie masz uprawnień do zapisu, w jaki sposób w projekcie akceptowane są zmiany? Czy ma on określoną politykę? Jak duże zmiany wgrywasz za jednym razem? Jak często je wgrywasz?
Odpowiedzi na wszystkie te pytania, mogą wpływać na to w jaki sposób będziesz wgrywał zmiany do repozytorium, oraz jaki rodzaj przepływu pracy jest najlepszy lub nawet dostępny dla Ciebie. Omówię aspekty każdej z nich w serii przypadków użycia, przechodząc od prostych do bardziej złożonych, powinieneś móc skonstruować konkretny przepływ pracy który możesz zastosować w praktyce z tych przykładów.
Wskazówki wgrywania zmian
Zanim spojrzysz na poszczególne przypadki użycia, najpierw szybka informacja o treści komentarzy do zmian ("commit messages"). Dobre wytyczne do tworzenia commitów, oraz związanych z nią treścią komentarzy pozwala na łatwiejszą pracę z Gitem oraz innymi współpracownikami. Projekt Git dostarcza dokumentację która pokazuje kilka dobrych rad dotyczących tworzenia commit-ów i łat - możesz ją znaleźć w kodzie źródłowym Gita w pliku Documentation/SubmittingPatches.
Po pierwsze, nie chcesz wgrywać żadnych błędów związanych z poprawkami pustych znaków (np. spacji). Git dostarcza łatwy sposób do tego - zanim wgrasz zmiany, uruchom git diff --check, komenda ta pokaże możliwe nadmiarowe spacje. Poniżej mamy przykład takiej sytuacji, zamieniłem kolor czerwony na terminalu znakami X:
$ git diff --check
lib/simplegit.rb:5: trailing whitespace.
+ @git_dir = File.expand_path(git_dir)XX
lib/simplegit.rb:7: trailing whitespace.
+ XXXXXXXXXXX
lib/simplegit.rb:26: trailing whitespace.
+ def command(git_cmd)XXXX
Jeżeli uruchomisz tę komendę przed commit-em, dowiesz się czy zamierzasz wgrać zmiany które mogą zdenerwować innych programistów.
Następnie spróbuj w każdym commit-ie zawrzeć logicznie odrębny zestaw zmian. Jeżeli możesz, twórz nie za duże łatki - nie programuj cały weekend poprawiając pięć różnych błędów, aby następnie wszystkie je wypuścić w jednym dużym commit-cie w poniedziałek. Nawet jeżeli nie zatwierdzasz zmian w ciągu weekendu, użyj przechowalni ("stage"), aby w poniedziałek rozdzielić zmiany na przynajmniej jeden commit dla każdego błędu, dodając użyteczny komentarz do każdego commitu. Jeżeli niektóre ze zmian modyfikują ten sam plik, spróbuj użyć komendy git add --patch, aby częściowo dodać zmiany do przechowalni (dokładniej opisane to jest w rozdziale 6). Końcowa migawka projektu w gałęzi jest identyczna, nieważne czy zrobisz jeden czy pięć commitów, więc spróbuj ułatwić życie swoim współpracownikom kiedy będą musieli przeglądać Twoje zmiany. Takie podejście ułatwia również pobranie lub przywrócenie pojedynczych zestawów zmian w razie potrzeby. Rozdział 6 opisuje kilka ciekawych trików dotyczących nadpisywania historii zmian i interaktywnego dodawania plików do przechowalni - używaj ich do utrzymania czystej i przejrzystej historii.
Ostatnią rzeczą na którą należy zwrócić uwagę są komentarze do zmian. Tworzenie dobrych komentarzy pozwala na łatwiejsze używanie i współpracę za pomocą Gita. Generalną zasadą powinno być to, że treść komentarza rozpoczyna się od pojedynczej linii nie dłuższej niż 50 znaków, która zwięźle opisuje zmianę, następnie powinna znaleźć się pusta linia, a poniżej niej szczegółowy opis zmiany. Projekt Git wymaga bardzo dokładnych wyjaśnień motywujących twoją zmianę w stosunku do poprzedniej implementacji - jest to dobra wskazówka do naśladowania. Dobrym pomysłem jest używania czasu teraźniejszego w trybie rozkazującym. Innymi słowy, używaj komend. Zamiast "Dodałem testy dla" lub "Dodawania testów dla", użyj "Dodaj testy do". Poniżej znajduje się szablon komentarza przygotowany przez Tima Pope z tpope.net:
Krótki (50 znaków lub mniej) opis zmiany
Bardziej szczegółowy tekst jeżeli jest taka konieczność. Zawijaj
wiersze po około 72 znakach. Czasami pierwsza linia jest traktowana
jako temat wiadomości email, a reszta komentarza jako treść. Pusta
linia oddzielająca opis od streszczenia jest konieczna (chyba że
ominiesz szczegółowy opis kompletnie); narzędzia takie jak `rebase`
mogą się pogubić jeżeli nie oddzielisz ich.
Kolejne paragrafy przychodzą po pustej linii.
- wypunktowania są poprawne, również
- zazwyczaj łącznik lub gwiazdka jest używana do punktowania,
poprzedzona pojedynczym znakiem spacji, z pustą linią pomiędzy,
jednak zwyczaje mogą się tutaj różnić.
Jeżeli wszystkie Twoje komentarz do zmian będą wyglądały jak ten, współpraca będzie dużo łatwiejsza dla Ciebie i twoich współpracowników. Projekt Git ma poprawnie sformatowane komentarze, uruchom polecenie git log --no-merges na tym projekcie, aby zobaczyć jak wygląda ładnie sformatowana i prowadzona historia zmian.
W poniższych przykładach, i przez większość tej książki, ze względu na zwięzłość nie sformatowałem treści komentarzy tak ładnie; używam opcji -m do git commit. Rób tak jak mówię, nie tak jak robię.
Małe prywatne zespoły
Najprostszym przykładem który możesz spotkać, to prywatne repozytorium z jednym lub dwoma innymi współpracownikami. Jako prywatne, mam na myśli repozytorium z zamkniętym kodem źródłowym - nie dostępnym do odczytu dla innych.Ty i inny deweloperzy mają uprawniania do wgrywania ("push") swoich zmian.
W takim środowisku możesz naśladować sposób pracy znany z Subversion czy innego scentralizowanego systemu kontroli wersji. Nadal masz wszystkie zalety takie jak commitowanie bez dostępu do centralnego serwera, oraz prostsze tworzenie gałęzi i łączenie zmian, ale przepływ pracy jest bardzo podobny; główną różnicą jest to, że łączenie zmian wykonywane jest po stronie klienta a nie serwera podczas commitu.
Zobaczmy jak to może wyglądać, w sytuacji w której dwóch programistów rozpocznie prace z współdzielonym repozytorium. Pierwszy programista, John, klonuje repozytorium, wprowadza zmiany i zatwierdza je lokalnie. (Zamieniłem część informacji znakami ... aby skrócić przykłady.)
# Komputer Johna
$ git clone john@githost:simplegit.git
Initialized empty Git repository in /home/john/simplegit/.git/
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'removed invalid default value'
[master 738ee87] removed invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)
Drugi programista, Jessica, robi to samo — klonuje repozytorium i commituje zmianę:
# Komputer Jessici
$ git clone jessica@githost:simplegit.git
Initialized empty Git repository in /home/jessica/simplegit/.git/
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'add reset task'
[master fbff5bc] add reset task
1 files changed, 1 insertions(+), 0 deletions(-)
Następnie, Jessica wypycha swoje zmiany na serwer:
# Komputer Jessici
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> master
John próbuje również wypchnąć swoje zmiany:
# Komputer Johna
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'
John nie może wypchnąć swoich zmian, ponieważ w międzyczasie Jessica wypchnęła swoje. To jest szczególnie ważne do zrozumienia, jeżeli przywykłeś do Subversion, ponieważ zauważysz że każdy z deweloperów zmieniał inne pliki. Chociaż Subversion automatycznie połączy zmiany po stronie serwera jeżeli zmieniane były inne pliki, w Git musisz połączyć zmiany lokalnie. John musi pobrać zmiany Jessici oraz włączyć je do swojego repozytorium zanim będzie wypychał swoje zmiany:
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/master
W tym momencie lokalne repozytorium Johna wygląda podobnie do tego z rys. 5-4.
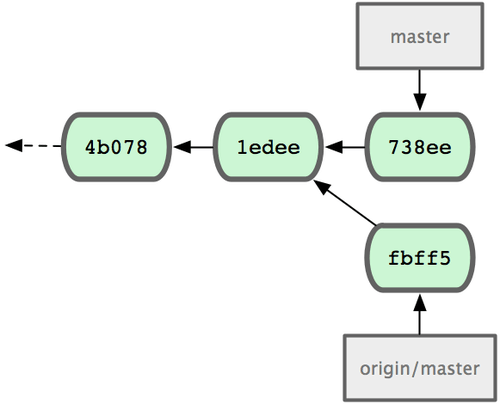
Figure 5-4. Lokalne repozytorium Johna.
John ma już odniesienie do zmian które wypchnęła Jessica, ale musi je lokalnie połączyć ze swoimi zmianami, zanim będzie w stanie wypchnąć je:
$ git merge origin/master
Merge made by recursive.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
Łączenie zmian poszło bez problemów - historia zmian u Johna wygląda tak jak na rys. 5-5.
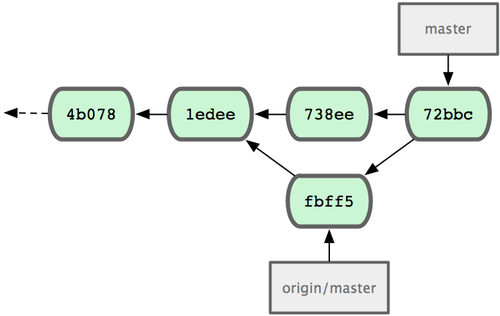
Figure 5-5. Repozytorium Johna po połączeniu z origin/master.
Teraz, John może przetestować swój kod aby upewnić się że nadal działa poprawnie, oraz następnie wypchnąć swoje zmiany na serwer:
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> master
Ostatecznie, historia zmian u Johna wygląda tak jak na rys. 5-6.
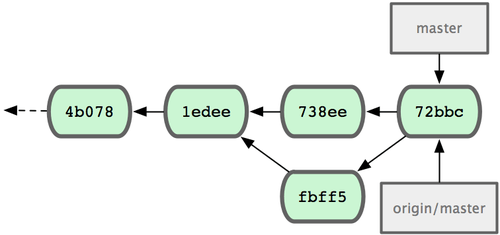
Figure 5-6. Historia zmian Johna po wypchnięciu ich na serwer "origin".
W tym samym czasie, Jessica pracowała na swojej tematycznej gałęzi. Stworzyła gałąź issue54 oraz wprowadziła trzy zmiany w niej. Nie pobrała jeszcze zmian Johna, więc jej historia zmian wygląda tak jak na rys. 5-7.
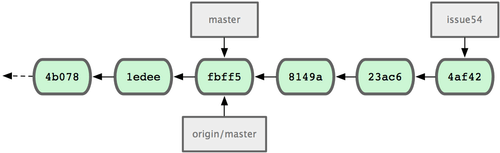
Figure 5-7. Początkowa historia zmian u Jessici.
Jessica chce zsynchronizować się ze zmianami Johna, więc pobiera ("fetch"):
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/master
Ta komenda pobiera zmiany Johna, które wprowadził w międzyczasie. Historia zmian u Jessici wygląda tak jak na rys. 5-8.
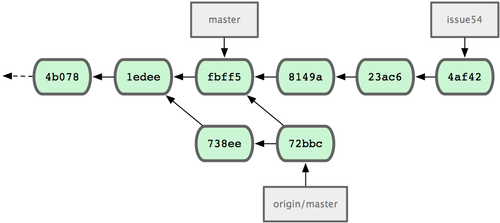
Figure 5-8. Historia zmian u Jessici po pobraniu zmian Johna.
Jessica uważa swoje prace w tej gałęzi za zakończone, ale chciałaby wiedzieć jakie zmiany musi włączyć aby mogła wypchnąć swoje. Uruchamia komendę git log aby się tego dowiedzieć:
$ git log --no-merges origin/master ^issue54
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <[email protected]>
Date: Fri May 29 16:01:27 2009 -0700
removed invalid default value
Teraz Jessica może połączyć zmiany ze swojej gałęzi z gałęzią "master", włączyć zmiany Johna (origin/master) do swojej gałęzi master, oraz następnie wypchnąć zmiany ponownie na serwer.
$ git checkout master
Switched to branch "master"
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.
Może ona włączyć origin/master lub issue54 jako pierwszą, obie są nadrzędne więc kolejność nie ma znaczenia. Końcowa wersja plików powinna być identyczna bez względu na kolejność którą wybierze; tylko historia będzie się lekko różniła. Wybiera pierwszą do włączenia gałąź issue54:
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)
Nie było problemów; jak widzisz był to proste połączenie tzw. fast-forward. Teraz Jessica może włączyć zmiany Johna (origin/master):
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
Wszystko połączyło się bez problemów, więc historia zmian u Jessici wygląda tak jak na rys. 5-9.
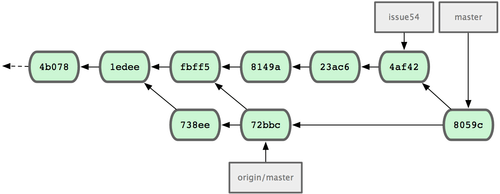
Figure 5-9. Historia zmian u Jessici po włączeniu zmian Johna.
Teraz origin/master jest dostępny z gałęzi master u Jessici, więc powinna bez problemów móc wypchnąć swoje zmiany (zakładając że w międzyczasie John nie wypchnął nic):
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> master
Każdy programista wprowadził zmiany kilkukrotnie, oraz połączył zmiany drugiego bez problemów; zobacz rys. 5-10.
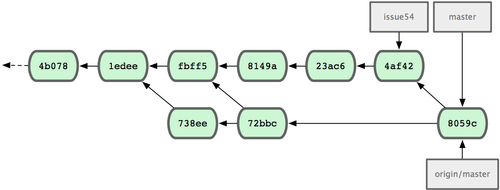
Figure 5-10. Historia zmian u Jessici po wypchnięciu zmian na serwer.
To jest jeden z najprostszych przepływów pracy. Pracujesz przez chwilę, generalnie na tematycznych gałęziach i włączasz je do gałęzi master kiedy są gotowe. Kiedy chcesz podzielić się swoją pracą, włączasz je do swojej gałęzi master, pobierasz i włączasz zmiany z origin/master jeżeli jakieś były, a następnie wypychasz gałąź master na serwer. Zazwyczaj sekwencja będzie wyglądała podobnie do tej pokazanej na rys. 5-11.
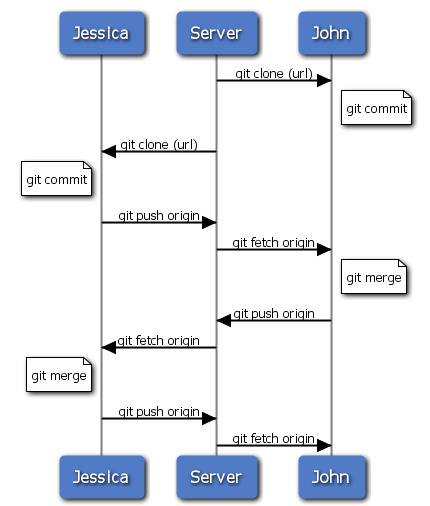
Figure 5-11. Sekwencja zdarzeń dla prostego przepływu zmian między programistami.
Prywatne zarządzane zespoły
W tym scenariuszu, zobaczysz jak działa współpraca w większych prywatnych grupach. Nauczysz się jak pracować w środowisku w którym małe grupy współpracują ze sobą nad funkcjonalnościami, a następnie stworzone przez nich zmiany są integrowane przez inną osobę.
Załóżmy że John i Jessica wspólnie pracują nad jedną funkcjonalnością, a Jessica i Josie nad drugą. W tej sytuacji, organizacja używa przepływu pracy z osobą integrującą zmiany, w której wyniki pracy poszczególnych grup są integrowane przez wyznaczone osoby, a gałąź master może być jedynie przez nie aktualizowana. W tym scenariuszu, cała praca wykonywana jest w osobnych gałęziach zespołów, a następnie zaciągana przez osoby integrujące.
Prześledźmy sposób pracy Jessici w czasie gdy pracuje ona nad obiema funkcjonalnościami, współpracując jednocześnie z dwoma niezależnymi programistami. Zakładając że ma już sklonowane repozytorium, rozpoczyna pracę nad funkcjonalnością featureA. Tworzy nową gałąź dla niej i wprowadza w niej zmiany:
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch "featureA"
$ vim lib/simplegit.rb
$ git commit -am 'add limit to log function'
[featureA 3300904] add limit to log function
1 files changed, 1 insertions(+), 1 deletions(-)
Teraz musi podzielić się swoją pracę z Johnem, więc wypycha zmiany z gałęzi featureA na serwer. Jessica nie ma uprawnień do zapisywania w gałęzi master - tylko osoby integrujące mają - musi więc wysłać osobną gałąź aby współpracować z Johnem:
$ git push origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureA
Jessica powiadamia Johna przez wiadomość e-mail, że wysłała swoje zmiany w gałęzi featureA i on może je zweryfikować. W czasie gdy czeka na informację zwrotną od Johna, Jessica rozpoczyna pracę nad featureB z Josie. Na początku, tworzy nową gałąź przeznaczoną dla nowej funkcjonalności, podając jako gałąź źródłową gałąź master na serwerze.
# Jessica's Machine
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch "featureB"
Następnie, Jessica wprowadza kilka zmian i zapisuje je w gałęzi featureB:
$ vim lib/simplegit.rb
$ git commit -am 'made the ls-tree function recursive'
[featureB e5b0fdc] made the ls-tree function recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'add ls-files'
[featureB 8512791] add ls-files
1 files changed, 5 insertions(+), 0 deletions(-)
Repozytorium Jessici wygląda tak jak na rys. 5-12.
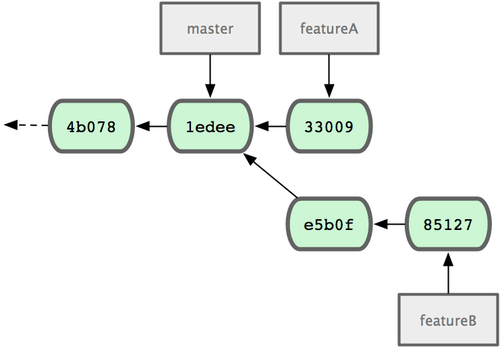
Figure 5-12. Początkowa historia zmian u Jessici.
Jest gotowa do wypchnięcia swoich zmian, ale dostaje wiadomość e-mail od Josie, że gałąź z pierwszymi zmianami została już udostępniona na serwerze jako featureBee. Jessica najpierw musi połączyć te zmiany ze swoimi, zanim będzie mogła wysłać je na serwer. Może więc pobrać zmiany Jose za pomocą komendy git fetch:
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBee
Jessica może teraz połączyć zmiany ze swoimi za pomocą git merge:
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)
Powstał drobny problem - musi wysłać połączone zmiany ze swojej gałęzi featureB do featureBee na serwerze. Może to zrobić poprzez wskazanie lokalnej i zdalnej gałęzi oddzielonej dwukropkiem (:), jako parametr do komendy git push:
$ git push origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBee
jest to nazywane refspec. Zobacz rozdział 9, aby dowiedzieć się więcej o refspecs i rzeczami które można z nimi zrobić.
Następnie John wysyła wiadomość do Jessici z informacją że wgrał swoje zmiany do gałęzi featureA i prosi ją o ich weryfikację. Uruchamia więc ona git fetch aby je pobrać:
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureA
Następnie, może ona zobaczyć co zostało zmienione za pomocą komendy git log:
$ git log origin/featureA ^featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <[email protected]>
Date: Fri May 29 19:57:33 2009 -0700
changed log output to 30 from 25
Na końcu, integruje ona zmiany Johna ze swoimi znajdującymi się w gałęzi featureA:
$ git checkout featureA
Switched to branch "featureA"
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Jessica postanawia jednak wprowadzić jeszcze jakieś zmiany, więc commituje je ponownie i wysyła je z powrotem na serwer:
$ git commit -am 'small tweak'
[featureA 774b3ed] small tweak
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push origin featureA
...
To jessica@githost:simplegit.git
3300904..774b3ed featureA -> featureA
Historia zmian u Jessici wygląda teraz tak jak na rys. 5-13.
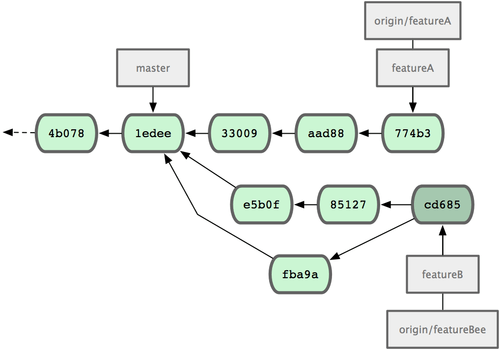
Figure 5-13. Historia zmian Jessici po wprowadzeniu zmian w gałęzi.
Jessica, Josie i John powiadamiają osoby zajmujące się integracją, że gałęzie featureA i featureBee na serwerze są gotowe do integracji z głównym kodem. Po włączeniu tych gałęzi do głównej, zostaną pobrane zmiany, tworząc historię zmian podobną do tej na rys. 5-14.
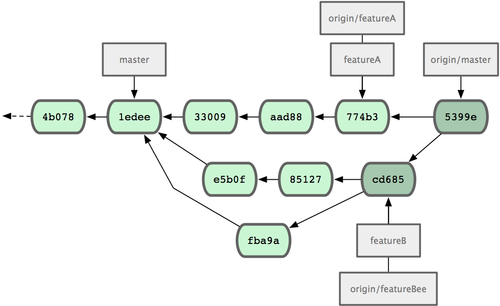
Figure 5-14. Historia zmian u Jessici po włączeniu jej obu gałęzi.
Duża ilość grup przechodzi na Gita ze względu na możliwość jednoczesnej współpracy kilku zespołów, oraz możliwości włączania efektów ich prac w późniejszym terminie. Możliwość tworzenie małych grup współpracujących przy pomocy zdalnych gałęzi bez konieczności angażowania pozostałych członków zespołu jest bardzo dużą zaletą Gita. Sekwencja przepływu pracy którą tutaj zobaczyłeś, jest podobna do tej na rys. 5-15.
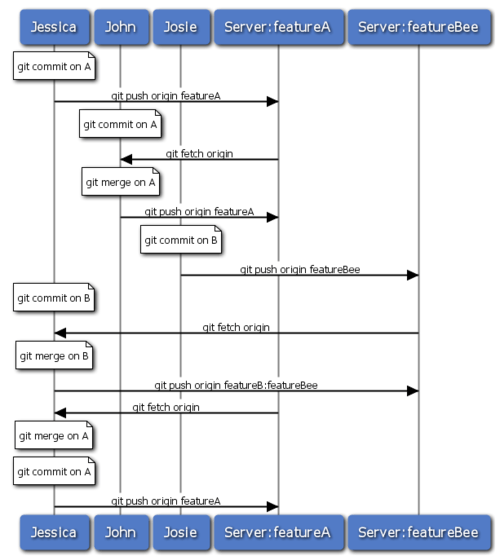
Figure 5-15. Przebieg zdarzeń w takim przepływie.
Publiczny mały projekt
Uczestniczenie w publicznym projekcie trochę się różni. Ponieważ nie masz uprawnień do bezpośredniego wgrywania zmian w projekcie, musisz przekazać swoje zmiany do opiekunów w inny sposób. Pierwszy przykład opisuje udział w projekcie poprzez rozwidlenie poprzez serwis który to umożliwia. Obie strony repo.or.cz oraz GitHub umożliwiają takie działanie, a wielu opiekunów projektów oczekuje takiego stylu współpracy. Następny rozdział opisuje współpracę w projektach, które preferują otrzymywanie łat poprzez wiadomość e-mail.
Po pierwsze, na początku musisz sklonować główne repozytorium, stworzyć gałąź tematyczną dla zmian które planujesz wprowadzić, oraz zmiany te zrobić. Sekwencja komend wygląda tak:
$ git clone (url)
$ cd project
$ git checkout -b featureA
$ (work)
$ git commit
$ (work)
$ git commit
Możesz chcieć użyć rebase -i, aby złączyć swoje zmiany do jednego commita, lub przeorganizować je, tak aby łata była łatwiejsza do opiekuna do przeglądu - zobacz rozdział 6, aby dowiedzieć się więcej o tego typu operacjach.
Kiedy zmiany w Twojej gałęzi zostaną zakończone i jesteś gotowy do przekazania ich do opiekunów projektu, wejdź na stronę projektu i kliknij przycisk "Fork", tworząc w ten sposób swoją własną kopię projektu z uprawnieniami do zapisu. Następnie musisz dodać nowe zdalne repozytorium, w tym przykładzie nazwane myfork:
$ git remote add myfork (url)
Musisz wysłać swoje zmiany do niego. Najprościej będzie wypchnąć lokalną gałąź na której pracujesz do zdalnego repozytorium, zamiast włączać zmiany do gałęzi master i je wysyłać. Warto zrobić tak dlatego, że w sytuacji w której Twoje zmiany nie zostaną zaakceptowane, lub zostaną zaakceptowane tylko w części, nie będziesz musiał cofać swojej gałęzi master. Jeżeli opiekun włączy, zmieni bazę lub pobierze część twoich zmian, będziesz mógł je otrzymać zaciągając je z ich repozytorium:
$ git push myfork featureA
Kiedy wgrasz wprowadzone zmiany do swojego rozwidlenia projektu, powinieneś powiadomić o tym opiekuna. Jest to często nazywane pull request, i możesz je wygenerować poprzez stronę - GitHub ma przycisk "pull request", który automatycznie generuje wiadomość do opiekuna - lub wykonaj komendę git request-pull i wyślij jej wynik do opiekuna projektu samodzielnie.
Komenda request-pull pobiera docelową gałąź do której chcesz wysłać zmiany, oraz adres URL repozytorium Gita z którego chcesz pobrać zmiany, oraz generuje podsumowanie zmian które będziesz wysyłał. Na przykład, jeżeli Jessica chce wysłać do Johna pull request, a wykonała dwie zmiany na swojej gałęzi którą właśnie wypchnęła, powinna uruchomić:
$ git request-pull origin/master myfork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
John Smith (1):
added a new function
are available in the git repository at:
git://githost/simplegit.git featureA
Jessica Smith (2):
add limit to log function
change log output to 30 from 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Wynik tej komendy może być wysłany do opiekuna - mówi on z której wersji została stworzona gałąź, podsumowuje zmiany, oraz pokazuje skąd można je pobrać.
W projekcie w którym nie jesteś opiekunem, najprostszym sposobem jest utrzymywanie gałęzi master która śledzi origin/master, a wprowadzać zmiany w tematycznych gałęziach, które możesz łatwo usunąć jeżeli zostaną odrzucone. Posiadanie oddzielnych gałęzi dla różnych funkcjonalności, ułatwia również tobie zmianę bazy ("rebase") jeżeli główna gałąź zostanie zmieniona i przygotowana łata nie może się poprawnie nałożyć. Na przykład, jeżeli chcesz wysłać drugi zestaw zmian do projektu, nie kontynuuj pracy na gałęzi którą właśnie wypchnąłeś - rozpocznij nową z gałąź master:
$ git checkout -b featureB origin/master
$ (work)
$ git commit
$ git push myfork featureB
$ (email maintainer)
$ git fetch origin
Teraz, każdy z zestawów zmian przechowywany jest w formie silosu - podobnego do kolejki z łatami - które możesz nadpisać, zmienić, bez konieczności nachodzenia na siebie, tak jak przedstawiono to na rys. 5-16.
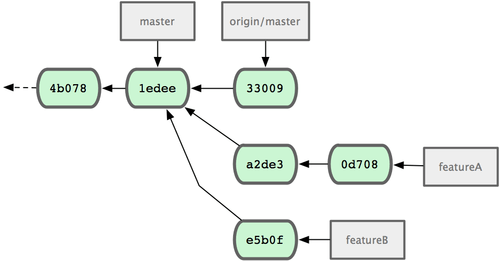
Figure 5-16. Początkowa historia ze zmianami featureB.
Załóżmy, że opiekun projektu pobrał Twoje zmiany i sprawdził twoją pierwszą gałąź, ale niestety nie aplikuje się ona czysto. W takiej sytuacji, możesz spróbować wykonać rebase na gałęzi origin/master, rozwiązać konflikty i ponownie wysłać zmiany:
$ git checkout featureA
$ git rebase origin/master
$ git push -f myfork featureA
To przepisuje twoją historię, która wygląda teraz tak jak na rys. 5-17.
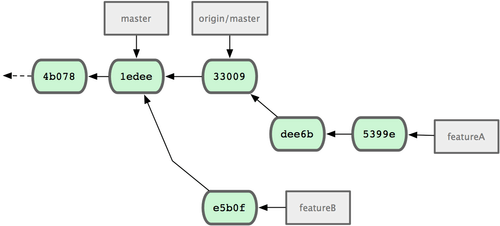
Figure 5-17. Historia zmian po pracach na featureA.
Z powodu zmiany bazy ("rebase") na gałęzi, musisz użyć przełącznika -f do komendy push, tak abyś mógł nadpisać gałąź featureA na serwerze, commitem który nie jest jej potomkiem. Alternatywą może być wysłanie tych zmian do nowej gałęzi na serwerze (np. nazwanej featureAv2).
Spójrzmy na jeszcze jeden scenariusz: opiekun spojrzał na zmiany w Twojej drugiej gałęzi i spodobał mu się pomysł, ale chciałby abyś zmienił sposób w jaki je zaimplementowałeś. Wykorzystasz to również do tego, aby przenieść zmiany do obecnej gałęzi master. Tworzysz więc nową gałąź bazując na origin/master, złączasz zmiany z gałęzi featureB tam, rozwiązujesz ewentualne konflikty, wprowadzasz zmiany w implementacji i następnie wypychasz zmiany do nowej gałęzi:
$ git checkout -b featureBv2 origin/master
$ git merge --no-commit --squash featureB
$ (change implementation)
$ git commit
$ git push myfork featureBv2
Opcja --squash pobiera wszystkie zmiany z gałęzi, oraz łączy je w jedną nie włączoną na gałęzi na której obecnie jesteś. Opcja --no-commit mówi Git aby nie zapisywał informacji o commit-cie. Pozwala to na zaimportowanie wszystkich zmian z innej gałęzi oraz wprowadzenie nowych przed ostatecznym zatwierdzeniem ich.
Teraz możesz wysłać do opiekuna wiadomość, że wprowadziłeś wszystkie wymagane zmiany, które może znaleźć w gałęzi featureBv2 (zob. rys. 5-18).
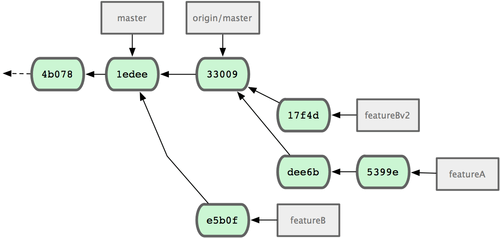
Figure 5-18. Historia zmian po zmianach w featureBv2.
Duży publiczny projekt
Duża ilość większych projektów ma ustalone reguły dotyczące akceptowania łat - będziesz musiał sprawdzić konkretne zasady dla każdego z projektów, ponieważ będą się różniły. Jednak sporo większych projektów akceptuje łatki poprzez listy dyskusyjne przeznaczone dla programistów, dlatego też opiszę ten przykład teraz.
Przepływ pracy jest podobny do poprzedniego - tworzysz tematyczne gałęzie dla każdej grupy zmian nad którymi pracujesz. Różnica polega na tym, w jaki sposób wysyłasz je do projektu. Zamiast tworzyć rozwidlenie i wypychać do niego zmiany, tworzysz wiadomość e-mail dla każdego zestawu zmian i wysyłasz je na listę dyskusyjną:
$ git checkout -b topicA
$ (work)
$ git commit
$ (work)
$ git commit
Teraz masz dwa commity, które chcesz wysłać na listę dyskusyjną. Uzyj git format-patch do wygenerowania plików w formacie mbox, które możesz wysłać na listę - zamieni to każdy commit w osobną wiadomość, z pierwszą linią komentarza ("commit message") jako tematem, jego pozostałą częścią w treści, dołączając jednoczenie zawartość wprowadzanej zmiany. Fajną rzeczą jest to, że aplikowanie łatki przesłanej przez e-mail i wygenerowanej za pomocą format-patch zachowuje wszystkie informacje o commit-cie, co zobaczysz w kolejnej sekcji kiedy zaaplikujesz te zmiany:
$ git format-patch -M origin/master
0001-add-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
Komenda format-patch wypisuje nazwy plików które stworzyła. Opcja -M mówi Git, aby brał pod uwagę również zmiany nazw plików. Zawartość plików w efekcie końcowym wygląda tak:
$ cat 0001-add-limit-to-log-function.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <[email protected]>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
1.6.2.rc1.20.g8c5b.dirty
Możesz oczywiście zmienić te pliki i dodać większą ilość informacji w mailu, których nie chciałeś pokazywać w komentarzu do zmiany. Jeżeli dodasz tekst miedzy linię z ---, oraz początkiem łaty (linia z lib/simplegit.rb), programiści będą mogli to przeczytać; ale podczas nakładania łaty zostanie do pominięte.
Aby wysłać to na listę dyskusyjną, możesz albo wkleić zawartość plików w programie e-mail lub użyć programu uruchamianego z linii komend. Wklejanie tekstu często wprowadza problemy z zachowaniem formatowania, szczególnie przy użyciu tych "mądrzejszych" programów pocztowych, które nie zachowują poprawnie znaków nowej linii i spacji. Na szczęście Git udostępnia narzędzie, które pomoże Ci wysłać poprawnie sformatowane łaty poprzez protokół IMAP, może to być łatwiejsze dla Ciebie. Pokażę w jaki sposób wysyłać łaty przy pomocy Gmaila, którego używam; możesz znaleźć bardziej szczegółowe instrukcje dla różnych programów pocztowych na końcu wcześniej wymienionego pliku Documentation/SubmittingPatches, który znajduje się w kodzie źródłowym Gita.
Najpierw musisz ustawić sekcję imap w swoim pliku ~/.gitconfig. Możesz ustawić każdą wartość oddzielnie przy pomocy kilku komend git config, lub możesz je dodać ręcznie; jednak w efekcie twój plik konfiguracyjny powinien wyglądać podobnie do:
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = [email protected]
pass = p4ssw0rd
port = 993
sslverify = false
Jeżeli twój serwer IMAP nie używa SSL, dwie ostatnie linie prawdopodobnie nie są potrzebne, a wartość host będzie imap:// zamiast imaps://. Po ustawieniu tego, możesz używać komendy git send-email aby umieścić łatki w folderze Draft na serwerze IMAP:
$ git send-email *.patch
0001-added-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
Who should the emails appear to be from? [Jessica Smith <[email protected]>]
Emails will be sent from: Jessica Smith <[email protected]>
Who should the emails be sent to? [email protected]
Message-ID to be used as In-Reply-To for the first email? y
Następnie, Git pokaże garść informacji podobnych tych, dla każdej łaty którą wysyłasz:
(mbox) Adding cc: Jessica Smith <[email protected]> from
\line 'From: Jessica Smith <[email protected]>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i [email protected]
From: Jessica Smith <[email protected]>
To: [email protected]
Subject: [PATCH 1/2] added limit to log function
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <[email protected]>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OK
Od tego momentu powinieneś móc przejść do folderu Draft, zmienić pole odbiorcy wiadomości na adres listy dyskusyjnej do której wysyłasz łatę, ewentualnie dodać adres osób zainteresowanych tym tematem w kopii i wysłać.
Podsumowanie
Ten rozdział opisywał kilka z najczęściej używanych sposobów przepływu pracy z różnymi projektami Git które możesz spotkać, oraz wprowadził kilka nowych narzędzi które ułatwiają ten proces. W następnych sekcjach zobaczysz jak pracować z drugiej strony: prowadząc projekt Gita. Nauczysz się jak być miłosiernym dyktatorem oraz osobą integrującą zmiany innych.